I often hear that Java atomic types (java.util.concurrent.atomic) are super-fast and play nicely with highly concurrent code. Most of the time, atomics do their job in a robust and efficient manner. However, there are scenarios in which the hidden cost of unmanaged contention on atomic types becomes a serious performance issue. Let’s take a look at how java.util.concurrent.atomic.Atomic* types are implemented and what that design implies.
All atomic types, such as AtomicLong, AtomicBoolean, AtomicReference, etc., are essentially wrappers for volatile values. The added value comes from internal use of sun.misc.Unsafe that delivers CAS capabilities to those types.
CAS (compare-and-swap) is in essence an atomic instruction implemented by modern CPU hardware that allows for non-blocking, multi-threaded data manipulation in a safe and efficient manner. The huge advantage of CAS over locking is the fact that CAS does not incur any overhead on the kernel level as no arbitrage takes place. Instead, the compiler emits CPU instructions such as lock cmpxchg, lock xadd, lock addq, etc. This is as fast as you can get with invoking instructions from a JVM perspective.
In many cases, low cost CAS gives an effective alternative for locking primitives but there is an exponentially growing cost of using CAS in contented scenarios.
This issue has been examined in a very interesting research by Dave Dice, Danny Hendler and Ilya Mirsky. I highly recommend reading the whole paper as it contains a lot more valuable information than this short article.
I reproduced some concepts from the paper and put them under test. Many Java programmers should find the results quite revealing since there is a common misconception about atomics (CAS) performance.
The code for implementing back-off contention management is fairly simple. Instead of looping over failed compare-and-swaps, it backs off for a very short period letting other threads try with their updates.
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.LockSupport;
public class BackOffAtomicLong {
public static long bk;
private final AtomicLong value = new AtomicLong(0L);
public long get() {
return value.get();
}
public long incrementAndGet() {
for (;;) {
long current = get();
long next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public boolean compareAndSet(final long current, final long next) {
if (value.compareAndSet(current, next)) {
return true;
} else {
LockSupport.parkNanos(1L);
return false;
}
}
public void set(final long l) {
value.set(l);
}
}The tests were executed on a 64-bit Linux 3.5.0 (x86_64) with Intel(R) Core(TM) i7-3632QM CPU @ 2.20GHz (8 logical cores) using 64-bit Hotspot Java 1.7.0_25-b15.
As expected, for high load contention there was no drastic difference between the two implementations:
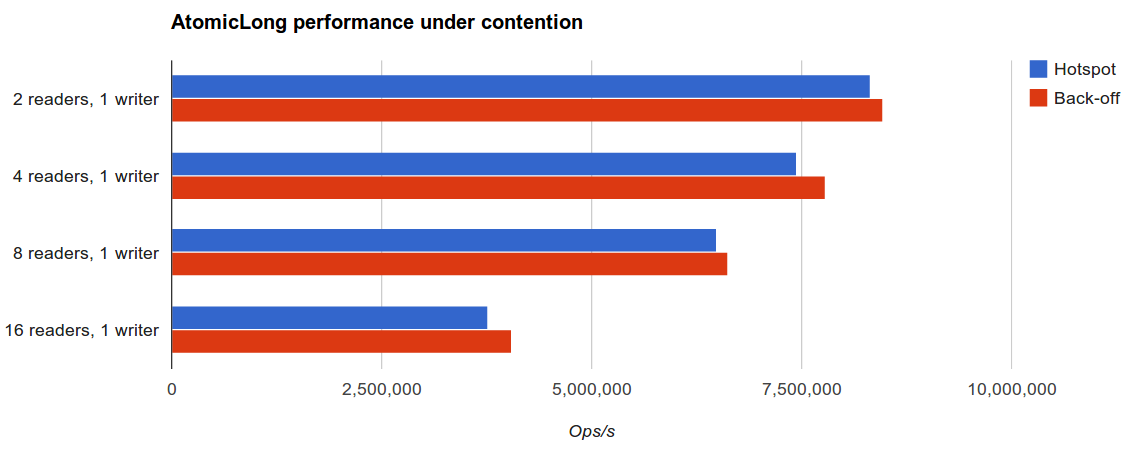
However, it gets far more interesting at high store contention. This scenario exposes the weakness of the optimistic retry approach employed by AtomicLong implementation from Hotspot.
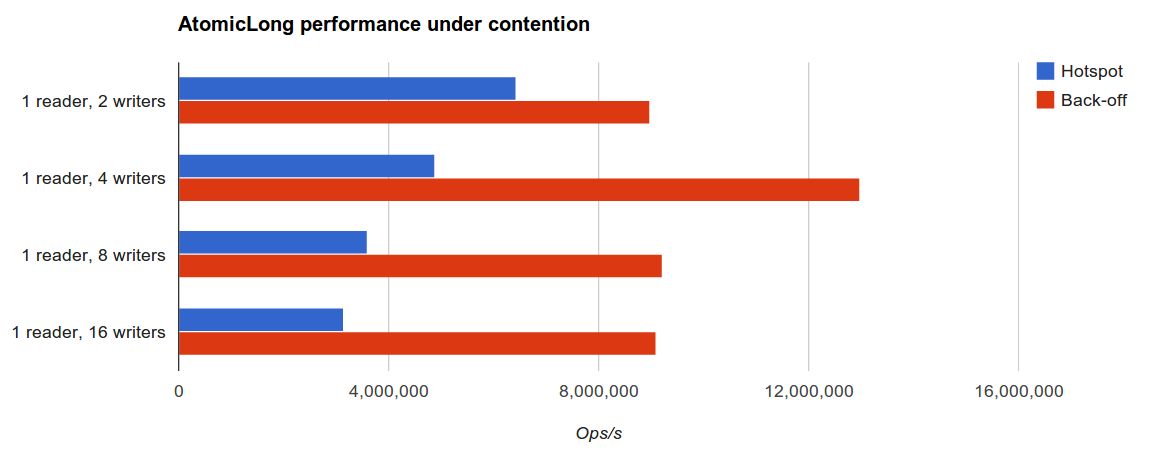
Similarly, with mixed reader/writer contention the benefits of lightweight access management are also clearly observable.

The results differ significantly when there is inter-socket communication involved, but unfortunately I somehow lost the output from testing against the Intel Xeon-based hardware. Feel free to post results for different architectures/JVMs.
