A metatrend going on in the IT industry is a shift from query-based, batch oriented systems to (soft) realtime updated systems. While this is associated with financial trading only, there are many other examples such as “Just-In-Time”-logistic systems, flight companies doing realtime pricing of passenger seats based on demand and load, C2C auction system like EBay, real time traffic control and many more.
It is likely this trend will continue, as the (commercial) value of information is time dependent, value decreases with age of information.
Automated trading in the finance sector is just a forerunner in this area, because some microseconds time advantage can be worth millions of dollars. Its natural real time processing systems evolve in this domain faster.
However big parts of traditional IT infrastructure is not designed for reactive, event based systems. From query based databases to request-response based Http protcol, the common paradigm is to store and query data “when needed”.
Current Databases are static and query-oriented
Current approaches to data management such as SQL and NOSQL databases focus on data transactions and static query of data. Databases provide convenience in slicing and dicing data but they do not support update of complex queries in real time. Uprising NOSQL databases still focus on computing a static result.
Databases are clearly not “reactive”.
Current Messaging Products provide poor query/filtering options
Current messaging products are weak at filtering. Messages are separated into different streams (or topics), so clients can do a raw preselection on the data received. However this frequently means a client application receives like 10 times more data than needed, doing fine grained filtering ‘on-top’.
A big disadvantage is, that the topic approach builts filter capabilities “into” the system’s data design.
E.g. if a stock exchange system splits streams on a per-stock base, a client application still needs to subscribe to all streams in order to provide a dynamically updated list of “most active” stocks. Querying usually means “replay+search the complete message history”.
A scalable, “continuous query” distributed Datagrid.
I had the enjoyment to do conceptional & technical design for a large scale realtime system, so I’d like to share a generic scalable solution for continuous query processing at high volume and large scale.
It is common, that real-time processing systems are designed “event sourced”. This means, persistence is replaced by journaling transactions. System state is kept in memory, the transaction journal is required for historic analysis and crash recovery only.
Client applications do not query, but listen to event streams instead. A common issue with event sourced systems is the problem of “late joining client”. A late client would have to replay the whole system event journal in order to get an up-to-date snapshot of the system state.
In order to support late joining clients, a kind of “Last Value Cache” (LVC) component is required. The LVC holds current system state and allows late joiners to bootstrap by querying.
In a high performance, large data system, the LVC component becomes a bottleneck as the number of clients rises.
Generalizing the Last Value Cache: Continuous Queries
In a continuous query data cache, a query result is kept up to date automatically. Queries are replaced by subscriptions.
subscribe * from Orders where symbol in ['ALV', 'BMW'] and volume > 1000 and owner='MyCompany'
creates a message stream, which initially performs a query operation, after that updates the result set whenever a data change affecting the query result happened (transparent to the client application). The system ensures each subscriber receives exactly the change notifications necessary to keep its “live” query results up-to-date.
Difference of data access patterns compared to static data management:
- High write volume
Real time systems create a high volume of write access/change in data. - Fewer full table scans.
Only late-joining clients or changes of a query’s condition require a full data scan. Because continuous queries make “refreshing” a query result obsolete, Read/Write ratio is ~ 1:1 (if one counts the change notification resulting from a transaction as “Read Access”). - The majority of load is generated, when evaluating queries of active continuous subscriptions with each change of data. Consider a transaction load of 100.000 changes per second with 10.000 active continuous queries: this requires 100.000*10.000 = 1 Billion evaluations of query conditions per second. That’s still an underestimation: When a record gets updated, it must be tested whether the record has matched a query condition before the update and whether it matches after the update. A record’s update may result in an add (because it matches after the change) or a remove transaction (because the record does not match anymore after a change) to a query subscription (or ‘update’, or ‘skip’ ofc).
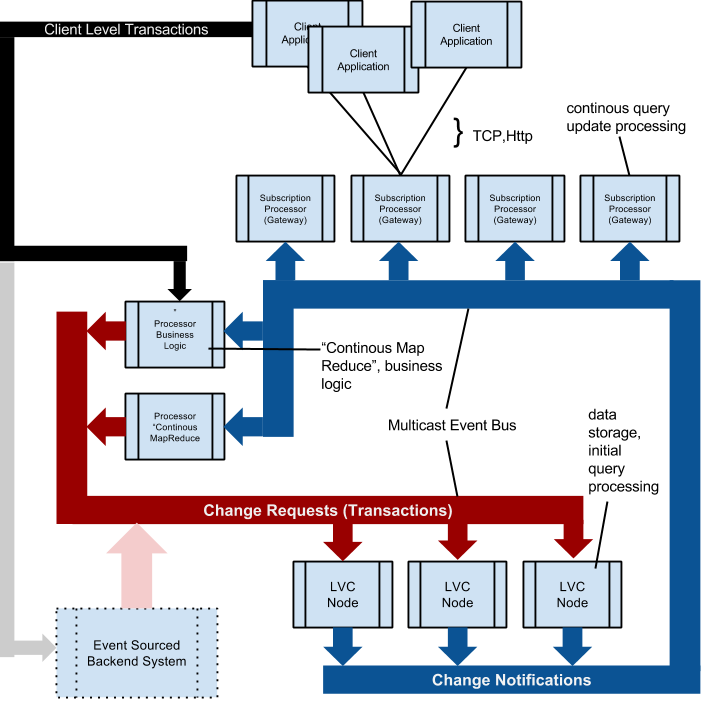
Data Cluster Nodes (“LastValueCache Nodes”)
Data is organized in tables, column oriented. Each table’s data is evenly partitioned amongst all data grid nodes (=last value cache node=”LVC node”). By adding data nodes to the cluster, capacity is increased and snapshot queries (initializing a subscription) are sped up by increased concurrency.
There are three basic transactions/messages processed by the data grid nodes:
- AddRow(table,newRow),
- RemoveRow(table,rowId),
- UpdateRow(table, rowId, diff).
The data grid nodes provide a lambda-alike (row iterator) interface supporting the iteration of a table’s rows using plain java code. This can be used to perform map-reduce jobs and as a specialization, the initial query required by newly subscribing clients. Since ongoing computation of continuous queries is done in the “Gateway” nodes, the load of data nodes and the number of clients correlate weakly only.
All transactions processed by a data grid node are (re-)broadcasted using multicast “Change Notification” messages.
Gateway Nodes
Gateway nodes track subscriptions/connections to client applications. They listen to the global stream of change notifications and check whether a change influences the result of a continuous query (=subscription). This is very CPU intensive.
Two things make this work:
- by using plain java to define a query, query conditions profit from JIT compilation, no need to parse and interpret a query language. HotSpot is one of the best optimizing JIT compilers on the planet.
- Since multicast is used for the stream of global changes, one can add additional Gateway nodes with ~no impact on throughput of the cluster.
Processor (or Mutator) Nodes
These nodes implement logic on-top of the cluster data. E.g. a statistics processor does a continuous query for each table, incrementally counts the number of rows of each table and writes the results back to a “statistics” table, so a monitoring client application can subscribe to realtime data of current table sizes. Another example would be a “Matcher processor” in a stock exchange, listening to orders for a stock, if orders match, it removes them and adds a Trade to the “trades” table.
If one sees the whole cluster as kind of a “giant spreadsheet”, processors implement the formulas of this spreadsheet.
Scaling Up
- with data size:
increase number of LVC nodes - Number of Clients
increase subscription processor nodes. - TP/S
scale up processor nodes and LVC nodes
Of cause the system relies heavily on availability of a “real” multicast messaging bus system. Any point to point oriented or broker-oriented networking/messaging will be a massive bottleneck.
Conclusion
Building real time processing software backed by a continuous query system simplifies application development a lot.
- Its model-view-controller at large scale.
Astonishing: patterns used in GUI applications for decades have not been extended regulary to the backing data storage systems. - Any server side processing can be partitioned in a natural way. A processor node creates an in-memory mirror of its data partition using continuous queries. Processing results are streamed back to the data grid. Computing intensive jobs, e.g. risk computation of derivatives can be scaled by adding processor instances subscribing to distinct partitions of the data (“sharding”).
- The size of the Code Base reduces significantly (both business logic and Front-End).
A lot of code in handcrafted systems deals with keeping data up to date.

a point in this process A scalable, “continuous query” distributed Datagrid. very hard how to understand it