Multi-tier application + database deadlock or why databases aren’t queues (part1)
Databases aren’t queues.
And despite the ubiquitous presence of queuing technology out there (ActiveMQ, MSMQ, MSSQL Service Broker, Oracle Advanced Queuing) there are plenty of times when we ask our relational brethren to pretend to be queues. This is the story of one such folly, and along the way, we’ll delve into some interesting sub-plots of deadlocks, lock escalation, execution plans, and covering indexes, oh my! Hopefully we’ll laugh, we’ll cry, and get the bad guy in the end (turned out I was the bad guy).
This is part one of a multi-part series describing the whole saga. In this part, I lay out the problem, the initial symptom, and the tools and commands I used to figure out what was going wrong.
And so it starts…
I’m going to set the stage for our discussion, to introduce you to the problem, and establish the characters involved in our tragedy. Let’s say that this system organizes music CDs into labeled buckets. A CD can only be in one bucket at a time, and the bucket tracks at an aggregate level how many CDs are contained within it (e.g. bucket “size”). You can visualize having a stack of CDs and two buckets: “good CDs” and “bad CDs”. Every once in a while you decide that you don’t like your bucket choices, and you want to redistribute the CDs into new buckets–perhaps by decade: “1980s music”, “1990s music”, “all other (inferior) music”. Later you might change your mind again and come up with a new way to organize your CDs, etc. We will call each “set” of buckets a “generation”. So at generation zero you had 2 buckets “good CDs” and “bad CDs”, at generation one you had “1980s CDs”, etc, and so on and so on. The generation always increases over time as you redistribute your CDs from a previous generation’s buckets to the next generation’s buckets.
Lastly, while I might have my music collection organized in some bucket scheme, perhaps my friend Jerry has his own collection and his own bucket scheme. So entire sets of buckets over generations can be grouped into music collections. Collections are completely independent: Jerry and I don’t share CDs nor do we share buckets. We just happen to be able to use the same system to manage our music collections.
So we have:
- CDs — the things which are contained within buckets, that we redistribute for every new generation
- Buckets — the organizational units, grouped by generation, which contain CDs. Each bucket has a sticky note on it with the number of CDs currently in the bucket.
- Generation — the set of buckets at a particular point in time.
- Collection — independent set of CDs and buckets
Even while we’re redistributing the CDs from one generation’s buckets to the next, a CD is only in one bucket at a time. Visualize physically moving the CD from “good CDs” (generation 0) to “1980s music” (generation 1).
NOTE: Our actual system has nothing to do with CDs and buckets– I just found it easier to map the system into this easy to visualize metaphor.
In this system we have millions of CDs, thousands of buckets, and lots of CPUs moving CDs from bins in one generation to the next (parallel, but not distributed). The size of each bucket must be consistent at any point in time.
So assume the database model looks something like:
- Buckets Table
- bucketId (e.g. 1,2,3,4) – PRIMARY KEY CLUSTERED
- name (e.g. 80s music, 90s music)
- generation (e.g. 0, 1, 2)
- size (e.g. 4323, 122)
- collectionId (e.g. “Steves Music Collection”) – NON-CLUSTERED INDEX
- Cds Table
- cdId (e.g. 1,2,3,4) – PRIMARY KEY CLUSTERED
- name (e.g. “Modest Mouse – Moon and Antarctica”, “Interpol – Antics”)
- bucketId (e.g. 1,2, etc. foreign key to the Bucket table) – NON-CLUSTERED INDEX
Note that both tables are clustered by their primary keys– this means that the actual record data itself is stored in the leaf nodes of the primary index. I.e. the table itself is an index. In addition, Buckets can be looked up by “music collection” without scanning (see the secondary, non-clustered index on collectionId), and Cds can be looked up by bucketId without scanning (see the secondary, non-clustered index on Cds.bucketId).
The algorithm
So I wrote the redistribution process with a few design goals: (1) it needed to work online. I could concurrently add new CDs into the current generations bins while redistributing. (2) I could always locate a CD– i.e. I could never falsely report that some CD was missing just because I happen to search during a redistribution phase. (3) if we interrupt the redistribution process, we can resume it later. (4) it needed to be parallel. I wanted to accomplish (1) and (2) with bounded blocking time so whatever blocking work I needed to do, I wanted it to be as short as possible to increase concurrency.
I used a simple concurrency abstraction that hosted a pool of workers who shared a supplier of work. The supplier of work would keep giving “chunks” of items to move from one bucket to another. We only redistribute a single music collection at a time. The supplier was shared by all of the workers, but it was synchronized for safe multi-threaded access.
The algorithm for each worker is like:
(I) Get next chunk of work
(II) For each CD decide the new generation bucket in which it belongs
(accumulating the size deltas for old buckets and new buckets)
(III) Begin database transaction
(IV) Flush accumulated size deltas for buckets
(V) Flush foreign key updates for CDs to put them in new buckets
(VI) Commit database transactionEach worker would be given a chunk of CDs for the current music collection that was being redistributed (I). The worker would do some work to decide which bucket in the new generation should get the CD (II). The worker would accumulate the deltas for counts: decrementing from the original bucket and incrementing the count for the new bucket. Then the worker would flush (IV) these deltas in a correlated update like UPDATE Buckets SET size = size + 123 WHERE bucketId = 1. After the size updates were flushed, it would then flush (V) all of the individual updates to the foreign key fields to refer to the new generations buckets like UPDATE Cds SET bucketId = 123 WHERE bucketId = 101. These two operations happen in the same database transaction. The supplier that gives work to the workers is a typical “queue” like SELECT query — we want to iterate over all of the items in the music collection in the old generation. This happens in a separate connection, separate database transaction from the workers (discussed later). The next chunk will be read using the worker thread (with thread safe synchronization). This separate “reader” connection doesn’t have its own thread or anything.
First sign of trouble – complete stand still
So we were doing some large volume testing on not-so-fast hardware, when suddenly…the system just came to a halt. We seemed to be in the middle of moving CDs to new buckets, and they just stopped making progress.
Finding out what the Java application was doing
So first step was to see what the Java application was doing:
c:\>jps 1234 BucketRedistributionMain 3456 jps c:\>jstack 1234 > threaddump.out
Jps finds the java process id, and then run jstack to output a stacktrace for each of the threads in the java program. Jps and Jstack are included in the JDK.
The resulting stack trace showed that all workers were waiting in socketRead to complete the database update to flush the bucket size updates (step IV above).
Here is the partial stack trace for one of the workers (some uninteresting frames omitted for brevity):
"container-lowpool-3" daemon prio=2 tid=0x0000000007b0e000 nid=0x4fb0 runnable [0x000000000950e000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(Unknown Source) ... at net.sourceforge.jtds.jdbc.SharedSocket.readPacket(Unknown) at net.sourceforge.jtds.jdbc.SharedSocket.getNetPacket(Unknown) ... at org.hibernate.jdbc.BatchingBatcher.doExecuteBatch(Unknown) ... at org.hibernate.impl.SessionImpl.flush(SessionImpl.java:1216) ... at com.mycompany.BucketRedistributor$Worker.updateBucketSizeDeltas() ... at java.util.concurrent.FutureTask$Sync.innerRun(Unknown Source) ... at java.lang.Thread.run(Unknown Source)
As you can see our worker was updating the bucket sizes which resulted in a Hibernate “flush” (actually pushes the database query across the wire to the database engine), and then we await the response packet from MSSQL once the statement is complete. Note that we are using the jtds MSSQL driver (as evidenced by the net.sourceforge.jtds in the stack trace.
So the next question is why is the database just hanging out doing nothing?
Finding out what the database was doing…
MSSQL provides a lot of simple ways to get insight into what the database is doing. First let’s see the state of all of the connections. Open SQL Server Management Studio (SSMS), click New Query, and type exec sp_who2
This will return output that looks like:
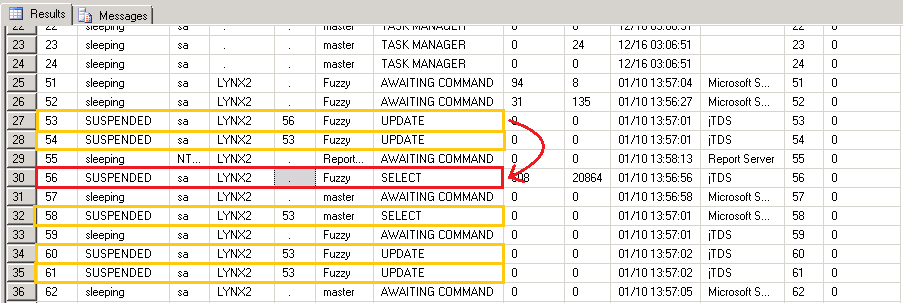
You can see all of the spids for sessions to the database. There should be five that we’re are interested in: one for the “work queue” query and four for the workers to perform updates. The sp_who2 output includes a blkBy column which shows the spid that is blocking the given spid in the case that the given spid is SUSPENDED.
We can see that spid 56 is the “work queue” SELECT query (highlighted red). Notice that no one is blocking it… then we see spids 53, 54, 60, and 61 (highlighted in yellow) that are all waiting on 56 (or each other). Disregard 58 – its application source is the management studio as you can see.
So how curious! the reader query is blocking all of the update workers and preventing them from pushing their size updates. The reader “work queue” query looks like:
SELECT c.cdId, c.bucketId FROM Buckets b INNER JOIN Cds c ON b.bucketId = c.bucketId WHERE b.collection = 'Steves Collection' and b.generation = 23
Investing blocking and locking problems…
I see that spid 56 is blocking everyone else. So what locks is 56 holding? In a new query window, I ran exec sp_lock 56 and exec sp_lock 53 to see which locks each was holding and who was waiting on what.
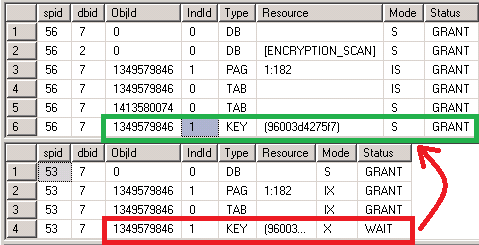
You can see that 56 was holding a S (shared) lock on a key resource (key = row lock on an index) of object 1349579846, which corresponds to the Buckets table.
I wanted to the engine’s execution plan for the reader “work queue” query. To get this, I executed a query that I created a while ago to dump as many details about current sessions in the system as possible– think of it as a “super who2”:
select es.session_id, es.host_name, es.status as session_status, sr.blocking_session_id as req_blocked_by, datediff(ss, es.last_request_start_time, getdate()) as last_req_submit_secs, st.transaction_id as current_xaction_id, datediff(ss, dt.transaction_begin_time, getdate()) as xaction_start_secs, case dt.transaction_type when 1 then 'read_write' when 2 then 'read_only' when 3 then 'system' when 4 then 'distributed' else 'unknown' end as trx_type, sr.status as current_req_status, sr.wait_type as current_req_wait, sr.wait_time as current_req_wait_time, sr.last_wait_type as current_req_last_wait, sr.wait_resource as current_req_wait_rsc, es.cpu_time as session_cpu, es.reads as session_reads, es.writes as session_writes, es.logical_reads as session_logical_reads, es.memory_usage as session_mem_usage, es.last_request_start_time, es.last_request_end_time, es.transaction_isolation_level, sc.text as last_cnx_sql, sr.text as current_sql, sr.query_plan as current_plan from sys.dm_exec_sessions es left outer join sys.dm_tran_session_transactions st on es.session_id = st.session_id left outer join sys.dm_tran_active_transactions dt on st.transaction_id = dt.transaction_id left outer join (select srr.session_id, srr.start_time, srr.status, srr.blocking_session_id, srr.wait_type, srr.wait_time, srr.last_wait_type, srr.wait_resource, stt.text, qp.query_plan from sys.dm_exec_requests srr cross apply sys.dm_exec_sql_text(srr.sql_handle) as stt cross apply sys.dm_exec_query_plan(srr.plan_handle) as qp) as sr on es.session_id = sr.session_id left outer join (select scc.session_id, sct.text from sys.dm_exec_connections scc cross apply sys.dm_exec_sql_text(scc.most_recent_sql_handle) as sct) as sc on sc.session_id = es.session_id where es.session_id >= 50
In the above output, the last column is the SQL XML Execution plan. Viewing that for spid 56, I confirmed my suspicion: The plan to serve the “work queue” query was to seek the “music collection” index on the buckets table for ‘Steves collection’, then seek to the clustered index to confirm ‘generation = 23’, then seek into the bucketId index on the Cds table. So to serve the WHERE clause in the “work queue” query, the engine had to use both the non-clustered index on Buckets and the clustered index (for the version predicate).
When joining and reading rows at READ COMMITTED isolation level, the engine will acquire locks as it traverses from index to index in order to ensure consistent reads. Thus, to read the value of the generation in the Buckets table, it must acquire a shared lock. And it has!
The problem comes in when the competing sessions that are trying to update the size on that same record of the Bucket table. It needs an X (exclusive) lock on that row (highlighted in red), and eek! it can’t get it, because that reader query has a conflicting S lock
already granted (highlighted in green).
Ok so that all makes sense, but why is the S lock being held? At READ COMMITTED you usually only hold the locks while the record is being read (there are exceptions and we’ll get to that in Part 2). They are released as soon as the value is read. So if you read 10 rows in a single statement execution, the engine will: acquire lock on row 1, read row 1, release lock on row 1, acquire lock on row 2, read row 2, release lock on row 2, acquire lock on row 3, etc. So none of the four workers are currently reading– they are writing — or at least they’re trying to if that pesky reader connection wasn’t blocking them.
To find this, I was curious why the reader query was in a SUSPENDED state (see original sp_who2 output above). In the above “super who2” output, the current_req_wait value for the “work queue” read query is ASYNC_Network_IO.
ASYNC_Network_IO wait and how databases return results
ASYNC_Network_IO is an interesting wait. Let’s discuss how remote applications execute and consume SELECT queries from databases.
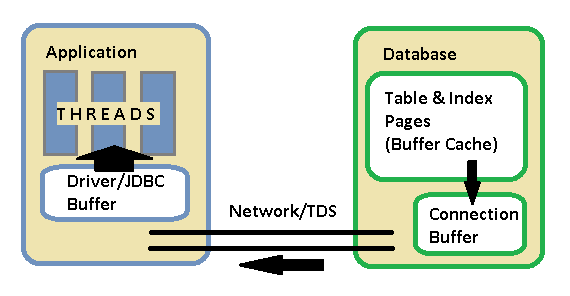
That diagram is over-simplified, but within the database there are two chunks of memory to discuss: the buffer cache and the connection network buffer. The buffer cache is a shared chunk of memory, where the actual pages of the tables and indexes are kept to serve queries. So parts of the Buckets and Cds tables will be in memory while this “work queue” query executes. The execution engine executes the plan, it works out of the buffer cache, acquiring locks, and producing output records to send to the client. As it prepares these output records, it puts them in a connection-specific network buffer. When the application reads records from the result set, its actually being served from the network buffer in the database. The application driver typically has its own buffer as well.
When you just execute a simple SQL SELECT query and don’t explicitly declare a database cursor, MSSQL gives you what it calls the “default result set” — which is still a cursor of sorts — you can think of it as a cursor over a bunch of records that you can only iterate over once in the forward direction. As your application threads iterate over the result set, the driver requests more chunks of rows from the database on your behalf, which in turn depletes the network buffer.
However, with very large result sets, the entire results cannot fit in the connection’s network buffer. If the application doesn’t read them fast enough, then eventually the network buffer fills up, and the execution engine must stop producing new result records to send to the client application. When this happens the spid must be suspended, and it is suspended with the wait event ASYNC_Network_IO. It’s a slightly misleading wait name, because it makes you think there might be a network performance problem, but its more often an application design or performance problem. Note that when the spid is suspended — just like any other suspension — the currently held locks will remain held until the spid is resumed.
In our case, we know that we have millions of CDs and we can’t fit them all in application memory at one time. We, by design, want to take advantage of the fact that we can stream results from the database and work on them in chunks. Unfortunately, if we happen to be holding a conflicting lock (S lock on Bucket record) when the reader query is suspended, then we create a multi-layer application deadlock, as we observed, and the whole system screeches to a halt.
So what to do for a solution? I will discuss some options and our eventual decision in Parts 2 and 3. Note that I gave one hint at our first attempt when I talked about “covering indexes”, and then there is another hint above that we didn’t get to in this post about “lock escalation”.

I would not have used relational database to model your problem. I have the feeling a graph database would have better fit your needs.
Am I right to conclude that once the read finishes, the workers will normally resume? I.e. no deadlocks, the system is just slower than expected?