We all have noticed that opening of a webpage for the first time takes some time, but the second or third time it loads faster. This happens because whenever we visit a webpage for the first time, our browser caches the content and need not have to make a call over the network to render it. This caching ability of the browser saves a lot of network bandwidth and helps in cutting down the server load.
1.) Browser or local Caches: This is the local in-memory cache of a browser. This is the fastest cache available. Whenever we hit a webpage a local copy is stored in browser and then second time it uses this local copy instead of making a real request over the network.
2.) Proxy Caches : These are pseudo web servers that work as middlemen between browsers and websites. These servers cache the static content and serve its clients so the client does not have to go to server for these resources.
The difference between local and proxy cache is that the former can’t serve more than one agent, so 2 identical requests from 2 consumers behind the same network effectively hit the origin server twice: again, needless to say, proxy caches serve cached responses slower than local ones.
Content Delivery Networks (CDN) are of similar concept wherein they provide proxy caches from their servers , which helps in faster serving the content and sharing the load of servers.
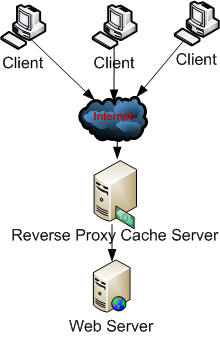
3.)Gateway Caches : A gateway cache is a cache served by a proxy installed on the server side, called reverse proxy.
It’s different from the proxy cache, in which the proxy stands into the client side: the advantage of implementing a gateway cache is that you can share the cache generated by a client with any other client of the planet doing the same request.
Inconsistency and invalidation: When we are dealing with cache we need to make sure that the stale data is invalidated and it should be consistent. So lets see what all mechanisms are provided by HTTP which can help us make effective use of HTTP caching.
HTTP Headers
Before HTTP1.1 the only way to control caching behaviour was with the help of “expries” header. In this an expiry date can be specified. But, later more powerful and extensive heades were introduced in HTTP1.1, this was “cache-control” header. This along with “etag” gave the real power to the applications to control the behaviour of caches.
JAX-RS supports these and provides APIs to use them. In the next blog we will see how to use JAX-RS to control the behaviour of caching in order to make best use out of it.
