Apache Mahout is a “scalable machine learning library” which, among others, contains implementations of various single-node and distributed recommendation algorithms. In my last blog post I described how to implement an on-line recommender system processing data on a single node. What if the data is too large to fit into memory (>100M preference data points)? Then we have no choice, but to take a look at Mahout’s distributed recommenders implementation!
The distributed recommender is based on Apache Hadoop; it’s a job which takes as input a list of user preferences, computes an item co-occurence matrix, and outputs top-K recommendations for each user. For an introductory blog on how this works and how to run it locally, see for example this blog post.
We can of course run this job on a custom Hadoop cluster, but it’s much faster (and less painful) to just use a pre-configured one, like EMR. However, there’s a slight problem. The latest Hadoop version that is available on EMR is 1.0.3, and it contains jars for Apache Lucene 2.9.4. However, the recommender job depends on Lucene 4.3.0, which results in the following beautiful stack trace:
2013-10-04 11:05:03,921 FATAL org.apache.hadoop.mapred.Child (main): Error running child : java.lang.NoSuchMethodError: org.apache.lucene.util.PriorityQueue.<init>(I)V at org.apache.mahout.math.hadoop.similarity.cooccurrence.TopElementsQueue.<init>(TopElementsQueue.java:33) at org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$UnsymmetrifyMapper. map(RowSimilarityJob.java:405) at org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$UnsymmetrifyMapper. map(RowSimilarityJob.java:389) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:771) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:375) at org.apache.hadoop.mapred.Child$4.run(Child.java:255) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1132) at org.apache.hadoop.mapred.Child.main(Child.java:249)
How to solve this? Well, we “just” need to update Lucene in the EMR Hadoop installation. We can use a bootstrap action for that. Here are the exact steps:
- Download lucene-4.3.0.tgz (e.g. from here) and upload it into a S3 bucket; make the file public.
- Upload this script to the bucket as well; call it e.g.
update-lucene.sh:#!/bin/bash cd /home/hadoop wget https://s3.amazonaws.com/bucket_name/bucket_path/lucene-4.3.0.tgz tar -xzf lucene-4.3.0.tgz cd lib rm lucene-*.jar cd .. cd lucene-4.3.0 find . | grep lucene- | grep jar$ | xargs -I {} cp {} ../libThis script will be run on the Hadoop nodes and will update the Lucene version. Make sure to change the script and enter the correct bucket name and bucket path, so that it points to the public Lucene archive.
- Finally, we need to upload the input data into S3. Output data will be saved on S3 as well.
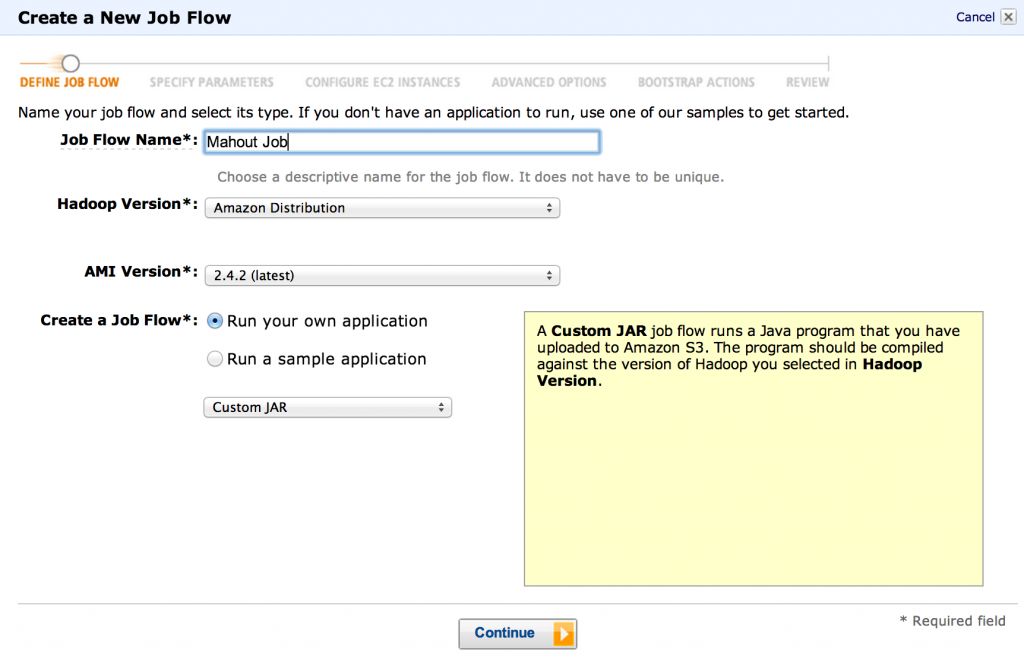
- Now we can start setting up the EMR job flow. Go to the EMR page on Amazon’s console, and start creating a new job flow. We’ll be using the “Amazon Distribution” Hadoop version and using a “Custom JAR” as the job type.

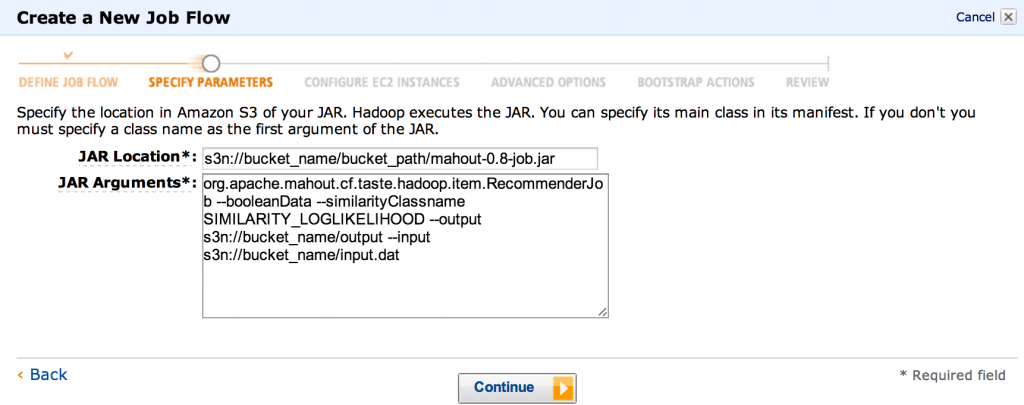
- The “JAR location” must point to the place where we’ve uploaded the Mahout jar, e.g.
s3n://bucket_name/bucket_path/mahout-0.8-job.jar(make sure to change this to point to the real bucket!). As for the jar arguments, we’ll be running theRecommenderJoband using the log-likelihood similarity:org.apache.mahout.cf.taste.hadoop.item.RecommenderJob --booleanData --similarityClassname SIMILARITY_LOGLIKELIHOOD --output s3n://bucket_name/output --input s3n://bucket_name/input.dat
That’s also the place to specify where the input data on S3 is, and where output should be written.

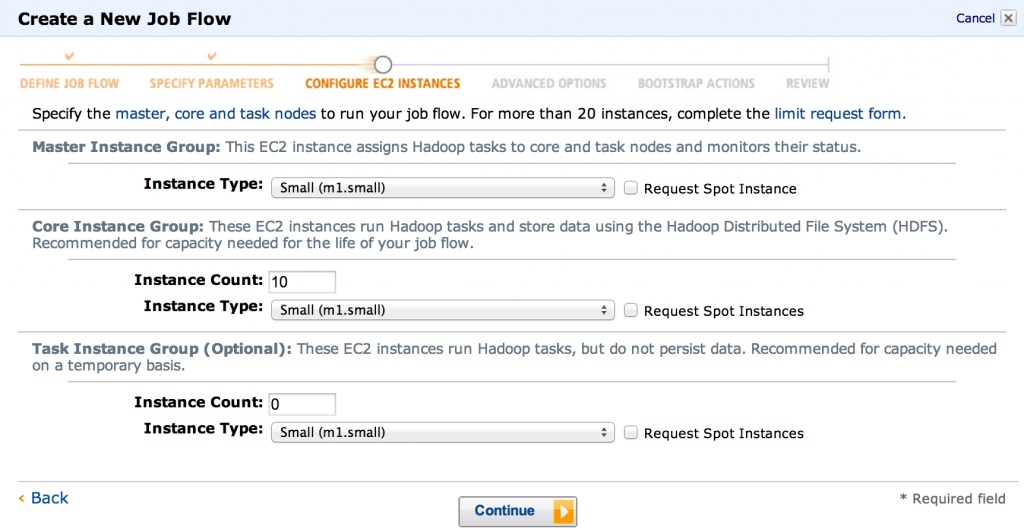
- Then we can choose how many machines we want to use. This depends of course on the size of the input data and how fast you want the results. The main thing to change here is the “core instance group” count. 2 is a reasonable default for testing.

- We can leave the advanced options as-is
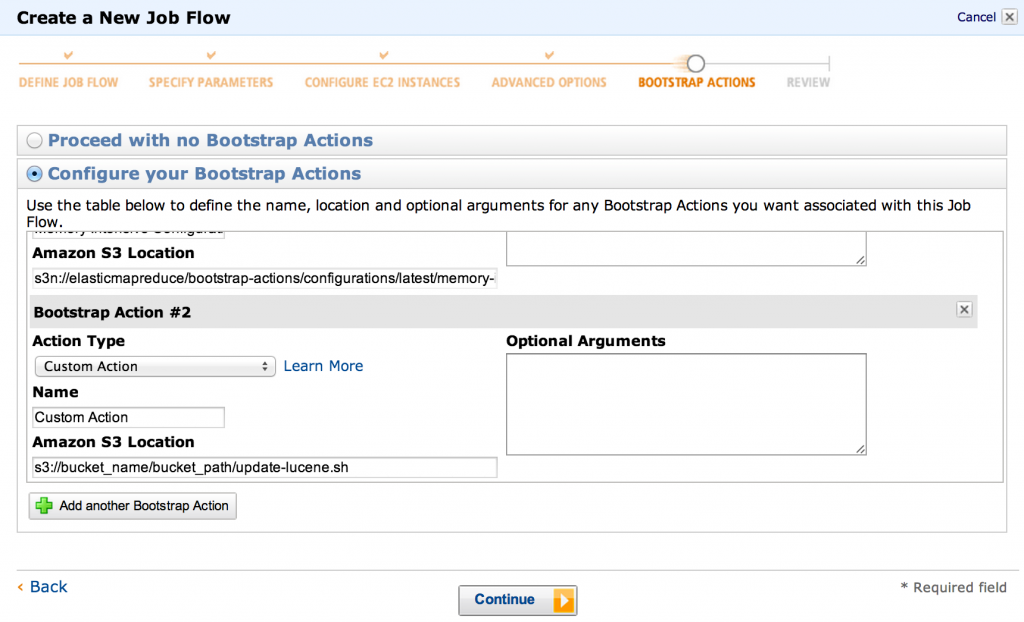
- Now we get to one of the more important steps: setting up bootstrap actions. We’ll need to setup two:
- a Memory Intenstive Configuration (otherwise you’ll see an OOM quickly)
- our custom update-lucene action (the path should point to S3, e.g.
s3://bucket_name/bucket_path/update-lucene.sh)

And that’s it! You can now create and run the job flow, and after a couple of minutes/hours/days you’ll have the results waiting on S3.
