I’m really excited about the forthcoming Fuse 6.1 release as there’s a ton of awesome new features which I’ve really wanted for some time and some really
hawt tooling .
So here’s a quick sneak peek, focussing mostly on the new version of the Fuse Management Console (which is now implemented by hawtio open source project).
A-MQ
First let me show you the A-MQ topology view which lets you view and create topologies of Apache ActiveMQ brokers in your fabric.
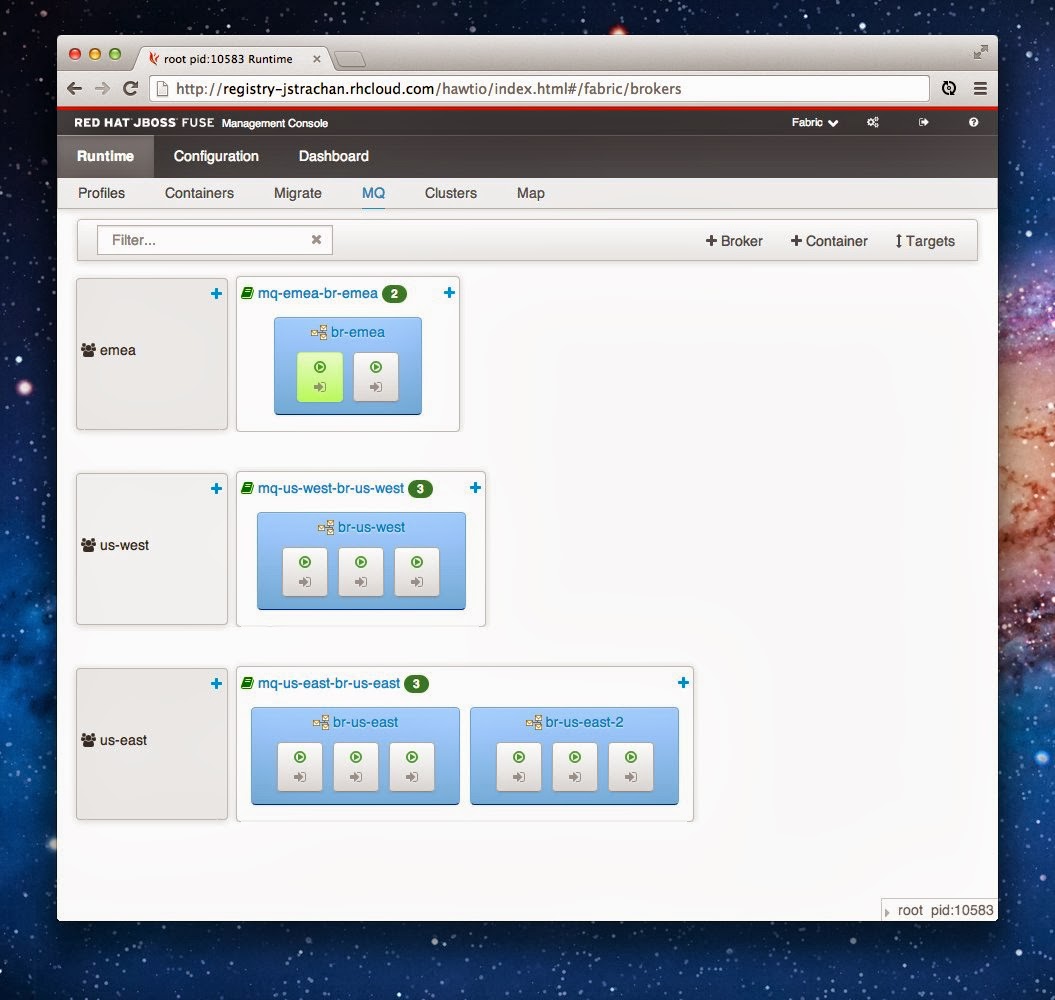
The green background is used to show the master broker (see the top row, the green master is on the left, the grey background container on the right is the slave). If in doubt, hover over the containers and the tooltip tells you whats going on or click on things to dive into the detail views.
For containers which are inactive, the green play icon becomes an orange stopped icon (or you see the provisioning icons as containers startup, download, provision etc). This view is real time so you can watch containers startup (which can take a little while if you’re using small gears on OpenShift ;).
If you click on the connect icon inside each container box, it takes you straight inside that broker; so you can view the destinations & see all the detailed metrics etc.
Incidentally the numbers in green badges next to the profile names show the number of containers running versus the required target number (like the new profile screen shows – see example below – the Target (requirements) versus Count (actual) columns). Again the tooltip gives a detailed explanation if you’re unsure
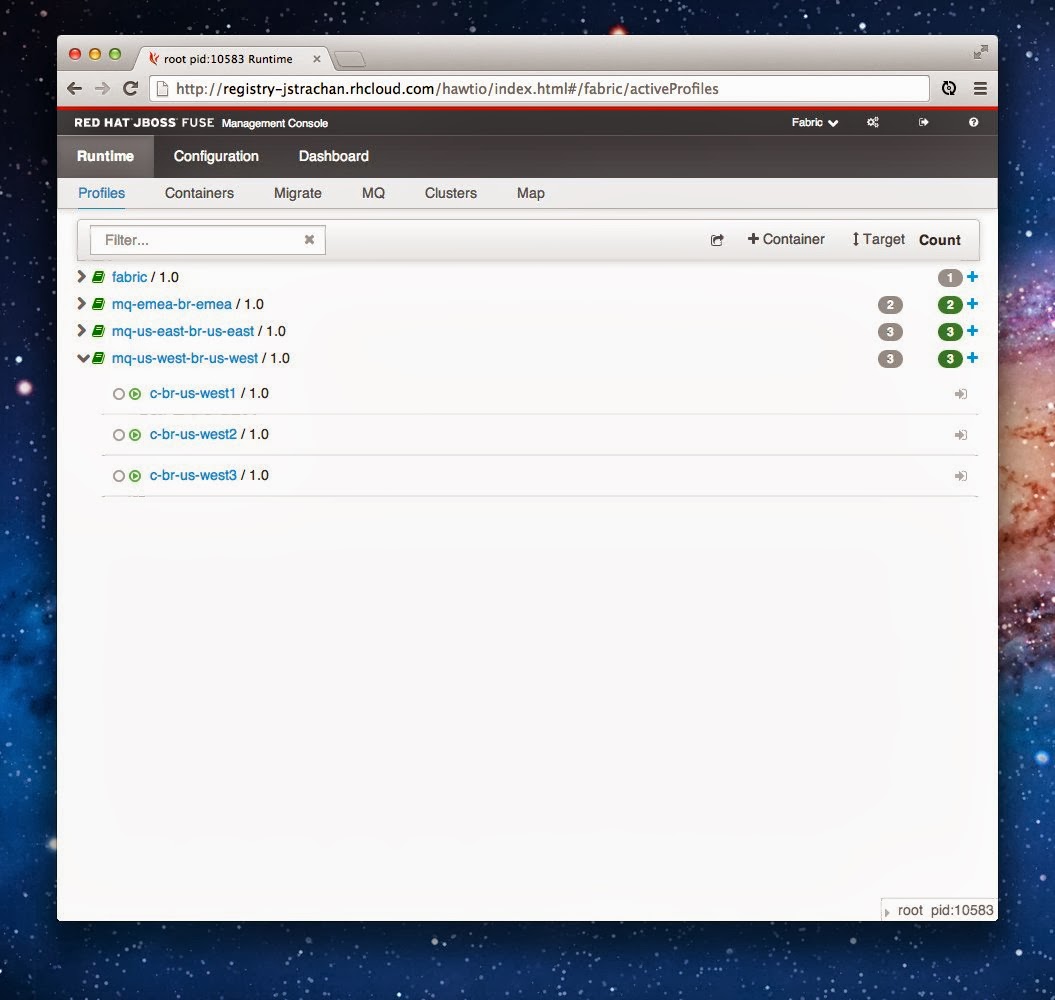
e.g. if you create a new broker config for a replicated broker; it by default creates a requirement for 3 containers to run for that profile (broker configuration); then you’d get a red icon until enough containers are running – and clicking the red badge takes you to the create containers page.
On OpenShift we’ve an auto-scaler, so as you add a new broker configuration, the containers would spin up immediately once the configuration is saved and you can watch them visually spin up (cool eh!).
To setup your own broker topology click the + Broker button to add new broker configurations (Stand Alone, Master / Slave, N + 1 or Replicated) and define the groups of brokers.
When using Fabric you can put brokers into groups (or ‘regions’). A group is just a name (or a path “us/east” if folks prefer); its just a String which is used to look in the right bit of ZooKeeper to find the brokers to connect to. So it can be a tree; though usually folks requirements are simple enough to just have either 1 global region; or have, say, 3 for different geo locations.
We can have a bunch of brokers in different groups, say, us-east, us-west, emea and messaging clients can then just use the right group name to connect to the right group of brokers. We use groups too for defining store/forward networks between groups. e.g. the us-east brokers may need to also store/forward with us-west brokers; they typically don’t care which broker they connect to – but just need to connect to a broker within the right group.
We can then create Fabric profiles for clients which are location specific. e.g. if you’ve a ‘cheese’ application (some web service or web app or whatnot) that needs to connect to A-MQ; we can have a cheese-us-east profile; which the only thing that profile does is it inherits from ‘cheese’ and just specifies the A-MQ group name of “us-east’ to connect to.
Longer term we hope to align the broker groups with OpenShift’s DNS/applications; so folks not using Fabric at all can just have the regions mapped to DNS names; e.g. “broker-us-east-foo.rhcloud.com” would be the host name to connect to an A-MQ broker and under the covers it does the DNS / haproxy crack to connect you to the right broker – without requiring any magic on the client side (other than knowing the right DNS/host name for the right group).
Dashboards
Also new in 6.1 is profile specific dashboards; so you can create custom dashboards for any profile which is based on the services running in that exact profile (i.e. a specific group of containers); then any container you connect to via the Fuse Management Console you get a nice easy view of the right things you want to see for that kind of profile.
e.g. here’s the default real time dashboard:
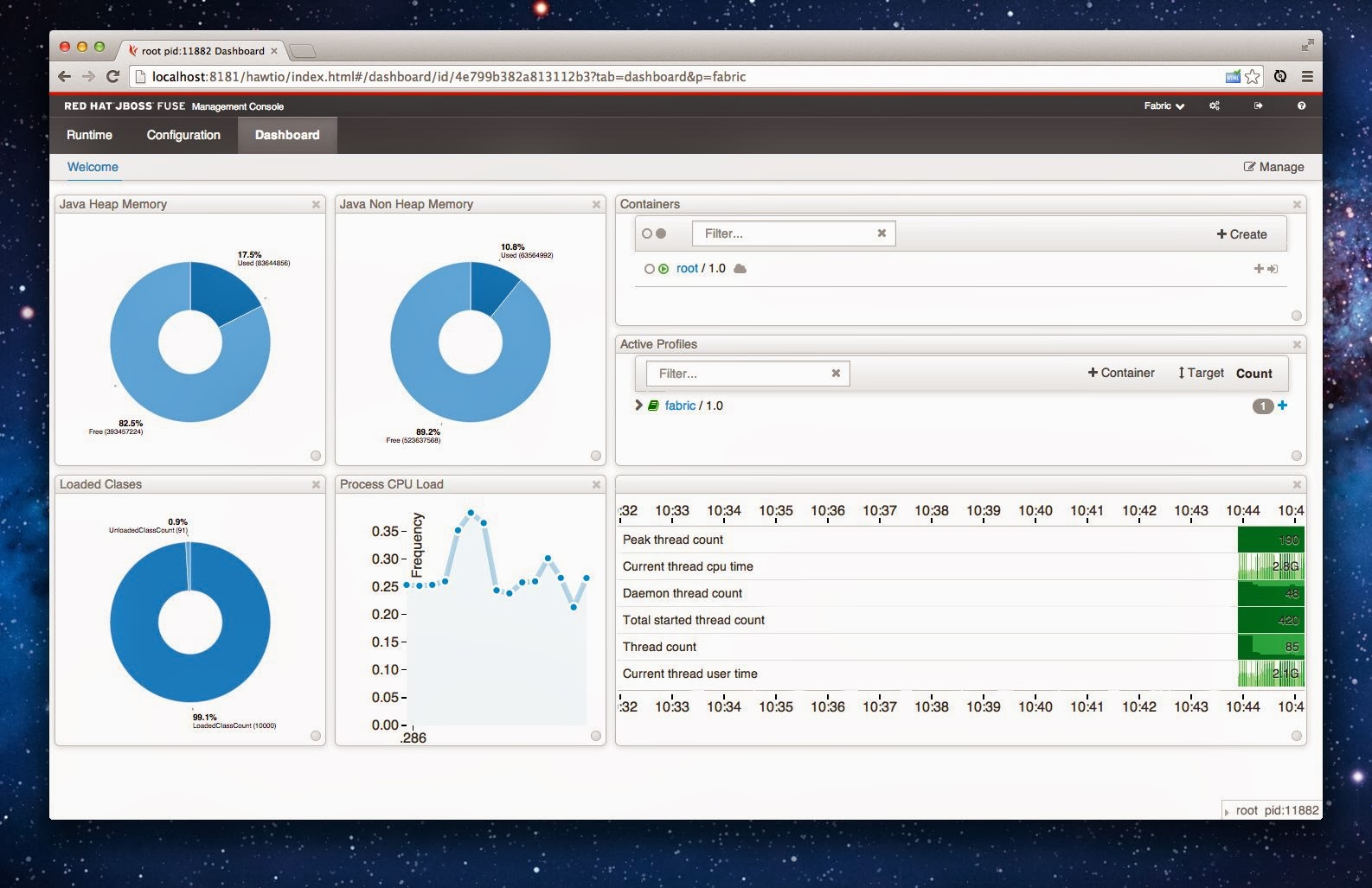
You can resize, move and add/edit/delete views in the usual way. Pretty much any UI in Fuse Management Console (which includes all the hawtio plugins) can be used as a rectangle on the dashboard; so you could add camel route metrics, log file searches or whatever).
Dashboards are then versioned and stored with all the other configuration. Which brings me to the configuration side…
Configuration gets git hawtness
Fuse Fabric is designed to make it really easy to manage large clusters of containers in a simple way; so you can group containers into
profiles. Then you can configure the profile & choose the exact deployment artefacts once and all the containers are updated immediately. You can use profile inheritance so you can configure groups of containers differently; e.g. use regional changes to some configuration values; increase the RAM/cache/disk usage settings on bigger boxes etc.
Finally you can version your profiles; so that rather than changes to a profile becoming immediate on all containers; you can create a new version; edit the profiles – then perform a rolling upgrade; choose which containers to upgrade, try them for a while, if things look good, roll more containers to the new version – or rollback if things go bad.
In Fuse 6.1 we have support for working with the configuration using the git source control system and its associated tools. This means that all changes to configuration, deployment units, dashboards, the wiki, camel routes and broker topologies all has a nice audit log of who changed what when; its easy to use all the available git tools to do diffs and revert changes, merge between branches/repos etc.
This means the configuration can work nicely with Continuous Integration and Continuous Deployment systems (e.g. using gerrit and jenkins). e.g. define all your profiles and configuration in development; then through Continuous Integration and Continuous Deployment builds and code review systems like gerrit, merge changes from development -> integration test -> soak test -> production etc.
Using git with Fuse 6.1
If you view any container’s page like below and click on the URLs tab:
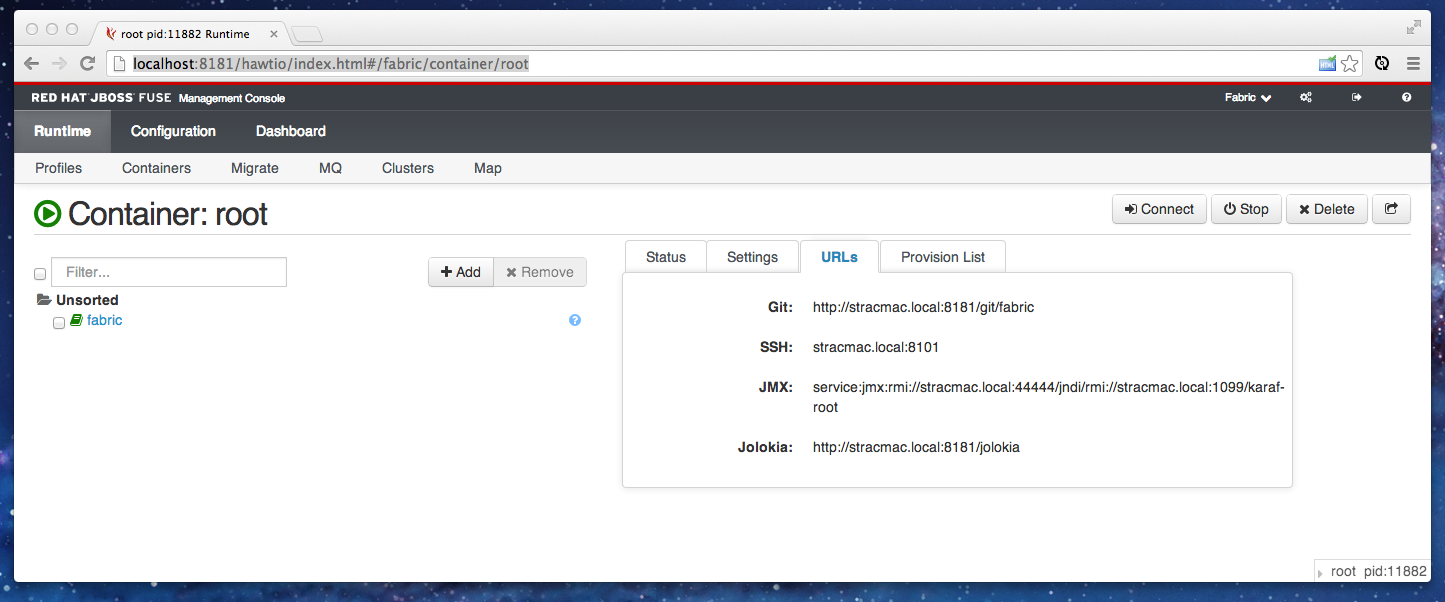
it shows the git url; so just do a git clone of that; then checkout the branch for the version you want to work with. (In 6.1 of Fuse, a version maps to the name of a branch in git).
git clone http://localhost:8181/git/fabric cd fabric git checkout -t origin/1.0 ls -al fabric/profiles
you can then hack on the profile data using any editor you like (they are just folders of config files) then commit and git push to make the changes active! Or make your own branches and so forth.
Whats really cool is that the wiki (where you can document all your applications and profiles) is versioned in the same git repository as your dashboards and configuration. So if you add a new version of a service in a new version of a profile; the dashboard can be updated to show new metrics; then whatever version is running you see the right wiki, documentation and dashboard for the exact version!
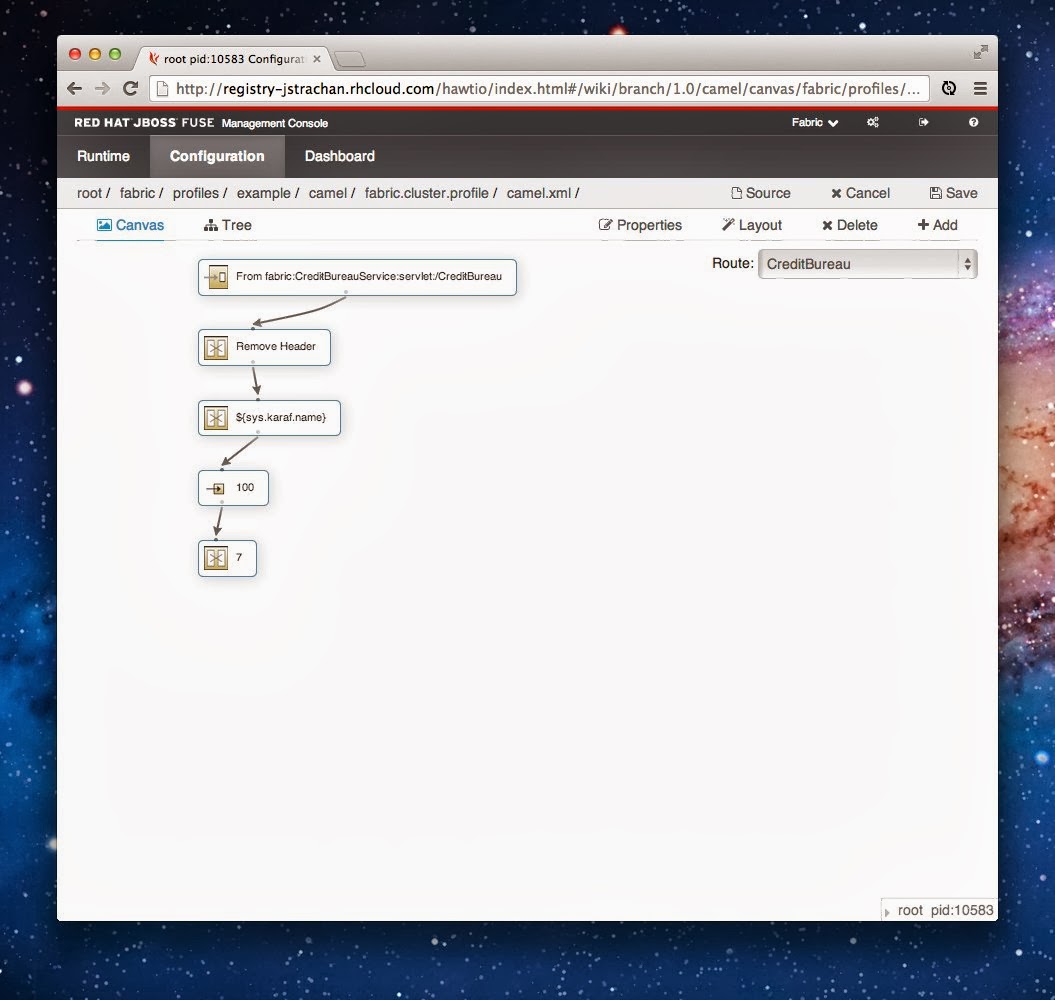
Camel editor and debugger included
Last but not least; 6.1 includes web based editing, viewing (with real time metrics and debugging of camel routes. The camel routes can be versioned in profiles; so you can do rolling upgrades of your camel routes with all changes audited and browsable in a git repository.
Summary
No blogging for months and then I write a huge post, sorry! If the above was too long just think, Fuse 6.1 has an awesome improved web console (based on the hawtio open source project) and lets you work with all the configuration in git so all changes are audited and you can easily combine Fuse 6.1 with any git, Continuous Integration or Continuous Deployment tooling for all your provisioning & configuration data. There’s lots more 6.1; I’ll have to try blog more often!
