I have posted a while ago how to setup an EMR cluster by using CLI. In this post I will show how to setup the cluster by using the Java SDK for AWS. The best way to show how to do this with the Java AWS SDK is to show the complete example in my opinion, so lets start.
- Set up a new Maven project
For this task I created a new default Maven project. The main class in this project is the one that you can run to initiate the EMR cluster and perform the MapReduce job I created in this post:
package net.pascalalma.aws.emr;
import com.amazonaws.AmazonServiceException;
import com.amazonaws.auth.AWSCredentials;
import com.amazonaws.auth.PropertiesCredentials;
import com.amazonaws.regions.Region;
import com.amazonaws.regions.Regions;
import com.amazonaws.services.ec2.model.InstanceType;
import com.amazonaws.services.elasticmapreduce.AmazonElasticMapReduceClient;
import com.amazonaws.services.elasticmapreduce.model.*;
import com.amazonaws.services.elasticmapreduce.util.StepFactory;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.AmazonS3Client;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.UUID;
/**
* Created with IntelliJ IDEA.
* User: pascal
* Date: 22-07-13
* Time: 20:45
*/
public class MyClient {
private static final String HADOOP_VERSION = "1.0.3";
private static final int INSTANCE_COUNT = 1;
private static final String INSTANCE_TYPE = InstanceType.M1Small.toString();
private static final UUID RANDOM_UUID = UUID.randomUUID();
private static final String FLOW_NAME = "dictionary-" + RANDOM_UUID.toString();
private static final String BUCKET_NAME = "map-reduce-intro";
private static final String S3N_HADOOP_JAR =
"s3n://" + BUCKET_NAME + "/job/MapReduce-1.0-SNAPSHOT.jar";
private static final String S3N_LOG_URI = "s3n://" + BUCKET_NAME + "/log/";
private static final String[] JOB_ARGS =
new String[]{"s3n://" + BUCKET_NAME + "/input/input.txt",
"s3n://" + BUCKET_NAME + "/result/" + FLOW_NAME};
private static final List<String> ARGS_AS_LIST = Arrays.asList(JOB_ARGS);
private static final List<JobFlowExecutionState> DONE_STATES = Arrays
.asList(new JobFlowExecutionState[]{JobFlowExecutionState.COMPLETED,
JobFlowExecutionState.FAILED,
JobFlowExecutionState.TERMINATED});
static AmazonS3 s3;
static AmazonElasticMapReduceClient emr;
private static void init() throws Exception {
AWSCredentials credentials = new PropertiesCredentials(
MyClient.class.getClassLoader().getResourceAsStream("AwsCredentials.properties"));
s3 = new AmazonS3Client(credentials);
emr = new AmazonElasticMapReduceClient(credentials);
emr.setRegion(Region.getRegion(Regions.EU_WEST_1));
}
private static JobFlowInstancesConfig configInstance() throws Exception {
// Configure instances to use
JobFlowInstancesConfig instance = new JobFlowInstancesConfig();
instance.setHadoopVersion(HADOOP_VERSION);
instance.setInstanceCount(INSTANCE_COUNT);
instance.setMasterInstanceType(INSTANCE_TYPE);
instance.setSlaveInstanceType(INSTANCE_TYPE);
// instance.setKeepJobFlowAliveWhenNoSteps(true);
// instance.setEc2KeyName("4synergy_palma");
return instance;
}
private static void runCluster() throws Exception {
// Configure the job flow
RunJobFlowRequest request = new RunJobFlowRequest(FLOW_NAME, configInstance());
request.setLogUri(S3N_LOG_URI);
// Configure the Hadoop jar to use
HadoopJarStepConfig jarConfig = new HadoopJarStepConfig(S3N_HADOOP_JAR);
jarConfig.setArgs(ARGS_AS_LIST);
try {
StepConfig enableDebugging = new StepConfig()
.withName("Enable debugging")
.withActionOnFailure("TERMINATE_JOB_FLOW")
.withHadoopJarStep(new StepFactory().newEnableDebuggingStep());
StepConfig runJar =
new StepConfig(S3N_HADOOP_JAR.substring(S3N_HADOOP_JAR.indexOf('/') + 1),
jarConfig);
request.setSteps(Arrays.asList(new StepConfig[]{enableDebugging, runJar}));
//Run the job flow
RunJobFlowResult result = emr.runJobFlow(request);
//Check the status of the running job
String lastState = "";
STATUS_LOOP:
while (true) {
DescribeJobFlowsRequest desc =
new DescribeJobFlowsRequest(
Arrays.asList(new String[]{result.getJobFlowId()}));
DescribeJobFlowsResult descResult = emr.describeJobFlows(desc);
for (JobFlowDetail detail : descResult.getJobFlows()) {
String state = detail.getExecutionStatusDetail().getState();
if (isDone(state)) {
System.out.println("Job " + state + ": " + detail.toString());
break STATUS_LOOP;
} else if (!lastState.equals(state)) {
lastState = state;
System.out.println("Job " + state + " at " + new Date().toString());
}
}
Thread.sleep(10000);
}
} catch (AmazonServiceException ase) {
System.out.println("Caught Exception: " + ase.getMessage());
System.out.println("Reponse Status Code: " + ase.getStatusCode());
System.out.println("Error Code: " + ase.getErrorCode());
System.out.println("Request ID: " + ase.getRequestId());
}
}
public static boolean isDone(String value) {
JobFlowExecutionState state = JobFlowExecutionState.fromValue(value);
return DONE_STATES.contains(state);
}
public static void main(String[] args) {
try {
init();
runCluster();
} catch (Exception e) {
e.printStackTrace();
}
}
}In this class I declare some constants first, I assume these will be obvious. In the init() method I use the credentials properties file that I added to the project. I added this file to the ‘/main/resources’ folder of my Maven project. It contains my access key and secret key.
Also I set the region to ‘EU-WEST’ for the EMR client.
The next method is ‘configInstance()’. In this method I create and configure the JobFlowInstance by setting the Hadoop version, number of instances, size of instances etc. Also you can configure the ‘keepAlive’ setting to keep the cluster alive after the jobs have finished. This could be helpful in some cases. If you want to use this option it might be useful to also set the key-pair you want to use to access the cluster because I wasn’t able to access the cluster without setting this key.
The method ‘runCluster()’ is were the cluster is actually run. It creates the request to initiate the cluster. In this request the steps are added that have to be executed. In our case one of the steps is running the JAR file we created in the previous steps. I also added a debug step so we have access to the debug logging after the cluster is finished and terminated. We can simply access the log files in the S3 bucket that I set with the constant ‘S3N_LOG_URI’.
When this request is created we start the cluster based on this request. Then we pull every 10 seconds to see whether the job has finished and show a message at the console indicating the current state of the job.
To execute the first run we have to prepare the input.
- Prepare the input
As input for the job (see this for more info about this example job) we have to make the dictionary contents available for the EMR cluster. Furthermore we have to make the JAR file available and make sure the output and log directory exists in our S3 buckets. There are several ways to do this: you can do this also programmatically by using the SDK, by using S3cmd to do it from the command line or by using the AWS Management Console. As long as you end up with a similar setup like this:
- s3://map-reduce-intro
- s3://map-reduce-intro/input
- s3://map-reduce-intro/input/input.txt
- s3://map-reduce-intro/job
- s3://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
- s3://map-reduce-intro/log
- s3://map-reduce-intro/result
Or when using S3cmd it looks like this:
s3cmd-1.5.0-alpha1$ s3cmd ls --recursive s3://map-reduce-intro/ 2013-07-20 13:06 469941 s3://map-reduce-intro/input/input.txt 2013-07-20 14:12 5491 s3://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar 2013-08-06 14:30 0 s3://map-reduce-intro/log/ 2013-08-06 14:27 0 s3://map-reduce-intro/result/
In the example above I already introduced an S3 client in the code. You can also use that to prepare the input or get the output as part of the client’s job.
- Run the cluster
When everything is in place we can run the job. I simply run the main method of ‘MyClient’ in IntelliJ and get the following output in my console:
Job STARTING at Tue Aug 06 16:31:55 CEST 2013
Job RUNNING at Tue Aug 06 16:36:18 CEST 2013
Job SHUTTING_DOWN at Tue Aug 06 16:38:40 CEST 2013
Job COMPLETED: {
JobFlowId: j-JDB14HVTRC1L
,Name: dictionary-8288df47-8aef-4ad3-badf-ee352a4a7c43
,LogUri: s3n://map-reduce-intro/log/,AmiVersion: 2.4.0
,ExecutionStatusDetail: {State: COMPLETED,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:36:14 CEST 2013
,ReadyDateTime: Tue Aug 06 16:36:14 CEST 2013
,EndDateTime: Tue Aug 06 16:39:02 CEST 2013
,LastStateChangeReason: Steps completed}
,Instances: {MasterInstanceType: m1.small
,MasterPublicDnsName: ec2-54-216-104-11.eu-west-1.compute.amazonaws.com
,MasterInstanceId: i-93268ddf
,InstanceCount: 1
,InstanceGroups: [{InstanceGroupId: ig-2LURHNAK5NVKZ
,Name: master
,Market: ON_DEMAND
,InstanceRole: MASTER
,InstanceType: m1.small
,InstanceRequestCount: 1
,InstanceRunningCount: 0
,State: ENDED
,LastStateChangeReason: Job flow terminated
,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:34:28 CEST 2013
,ReadyDateTime: Tue Aug 06 16:36:10 CEST 2013
,EndDateTime: Tue Aug 06 16:39:02 CEST 2013}]
,NormalizedInstanceHours: 1
,Ec2KeyName: 4synergy_palma
,Placement: {AvailabilityZone: eu-west-1a}
,KeepJobFlowAliveWhenNoSteps: false
,TerminationProtected: false
,HadoopVersion: 1.0.3}
,Steps: [
{StepConfig: {Name: Enable debugging
,ActionOnFailure: TERMINATE_JOB_FLOW
,HadoopJarStep: {Properties: []
,Jar: s3://us-east-1.elasticmapreduce/libs/script-runner/script-runner.jar
,Args: [s3://us-east-1.elasticmapreduce/libs/state-pusher/0.1/fetch]}
}
,ExecutionStatusDetail: {State: COMPLETED,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:36:12 CEST 2013
,EndDateTime: Tue Aug 06 16:36:40 CEST 2013
,}
}
, {StepConfig: {Name: /map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
,ActionOnFailure: TERMINATE_JOB_FLOW
,HadoopJarStep: {Properties: []
,Jar: s3n://map-reduce-intro/job/MapReduce-1.0-SNAPSHOT.jar
,Args: [s3n://map-reduce-intro/input/input.txt
, s3n://map-reduce-intro/result/dictionary-8288df47-8aef-4ad3-badf-ee352a4a7c43]}
}
,ExecutionStatusDetail: {State: COMPLETED
,CreationDateTime: Tue Aug 06 16:31:58 CEST 2013
,StartDateTime: Tue Aug 06 16:36:40 CEST 2013
,EndDateTime: Tue Aug 06 16:38:10 CEST 2013
,}
}]
,BootstrapActions: []
,SupportedProducts: []
,VisibleToAllUsers: false
,}
Process finished with exit code 0And of course we have a result in the ‘result’ folder that we configured in our S3 bucket:
![]()
I transfer the result to my local machine and have a look at it:
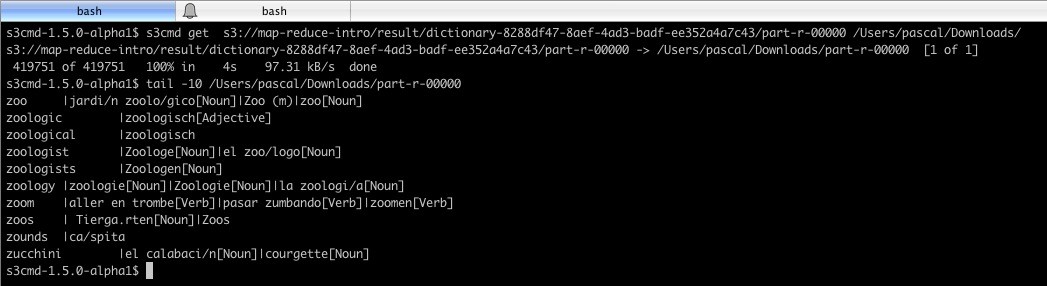
So that concludes this simple but I think rather complete example of creating an Hadoop job and run it on a cluster after having it unit tested as we would do with all our software.
With this setup as a base it is quite easy to come up with more complex business cases and have these tested and configured to be run on AWS EMR.

The Information was very much useful for Hadoop Online Training Learners Thank You for Sharing Valuable Information it is very useful for us.and we also providing Hadoop Online Training