Mongo: noun (pl mongo or mongos) – a monetary unit of Mongolia. Equal to one hundredth of a tugrik. Origin from Mongolian “silver”
I’ve written about NoSQL DBMS [http://keyholesoftware.com/2012/10/01/is-nosql-the-sql-sequel/]. We know that there are several categories of NoSQL DBMS. MongoDB is a scalable NoSQL document-oriented data store that has built-in geo-spatial indexing. Let’s look at its characteristics and then check out a mobile geo-spatial demo application.
MongoDB Characteristics
- No schema. An inserted document could have distinct attributes. This is a two-edged sword that enables rapidly changing an application, or easily accepting data with added or new attributes over time.
- No SQL query language. Carry out CRUD through an API that uses JSON instead of SQL query input.
- Document-oriented. View each record as a uniquely keyed JSON document within a collection. A database contains collections, not tables.
- BSON. I’m busted. MongoDB really uses BSON, a binary serialized rendition of JSON [http://bsonspec.org/]. Documents are stored as BSON, but JSON goes into MongoDB and JSON comes out of it. We can think of data as JSON unless we’re using a language binding than can use BSON directly.
- Types. There are UTF-8 strings, arrays, embedded documents, dates, regular expressions, booleans, 64-bit numbers, object ID (OID), binary, timestamp, and JavaScript code.
- Document-based query. Specify a JSON document as the find parameter. If none supplied the result is all documents, a page at a time.
- Index any document attribute. Attributes are JSON attribute names.
- Atomic update. Data updates strive to be in-place. The MongoDB server locks the entire collection until an update completes. If the document has to grow too much, the write becomes a copy-and-rewrite that is slower. We can check the outcome. Each document has padding to defend against excessive copy-and-rewrite.
- Write concern. MongoDB enables us to specify concern for the outcome of a write operation. The following increasingly picky kinds of write concern give an idea of the concept: all errors ignored, only a good write is unacknowledged, journaled protection in the event of a server shutdown, or all replicas have acknowledged the write.
- Replica set. This is a group of distributed MongoDB servers that share a single set of data. They elect a master. Fail-over entails the replica set automatically electing a new master. This provides high availability and redundancy.
- Eventual consistency. All members of a replica set strive to eventually synchronize with the elected master.
- Auto-sharding. MongoDB scales horizontally by partitioning a collection across servers. If we add a server, MongoDB automatically rebalances the collection data to the new server [http://docs.mongodb.org/manual/sharding/].
- Memory mapped. Data flows into and out of memory-mapped files that reflect disk storage.
- REST. The mongod server provides a simple read-only REST query interface. Some language bindings provide full-featured REST services [http://docs.mongodb.org/ecosystem/tools/http-interfaces/#HttpInterface-RESTInterfaces].
- Map-reduce. Complex aggregation tasks use map-reduce [http://docs.mongodb.org/manual/core/map-reduce/]. If a target collection is sharded, each shard server can process pieces of the map-reduce operation. Think of word-count as a trivial example suitable for map-reduce. Here all words in a query result reduce to a number.
- Aggregation. An aggregation framework enables obtaining aggregated values without resorting to the more-complex map-reduce. All documents pass through an aggregation pipeline where optional operators can filter the data. One operator is $sort, for example. Stateless expressions can produce output documents from the current document in the pipeline.
- GridFS. Files of any size can reside in a collection situated in 256K chunks across servers. We can position a read into the middle of a file without loading the data entirely into memory. The mongofiles command aids in manipulating GridFS files.
- Geo-spatial indexing. We can index any attribute. Moreover we can index some attributes spatially. If the attribute is composed of 2D or 3D numeric values as coordinates, you can index that attribute as a 2D or 3D spatial index. The coordinates are usually Earth locations, but game grids work. I’ll cover more about geo-spatial indexing in the next section.
- Capped collections. We can limit or cap a collection such that oldest documents disappear when the collection size reaches the cap limit. This is useful for logging and analytics. It could form an enterprise’s first foray into NoSQL.
- Shell. A built-in command-based client provides administration and query capability.
- HTTP Console. I access a built-in web-based console through a URL aimed at a port 1000 higher than that of the mongod server. E.g. for standard port 27017 on localhost, use http://localhost:28017/.
Geo-spatial database
I like geometry and maps [http://keyholesoftware.com/2013/01/28/mapping-shortest-routes-using-a-graph-database/]. I mentioned that MongoDB supports 2d geospatial indexes. Each entry can associate a document with a point in two-dimensional space. It could be a point on a map, or a point in a game grid. MongoDB supports the following kinds of location-based data using those indexes:
- Proximity queries that return documents as a function of distance to a supplied point.
- Bounded queries that choose documents having location values within a given region.
- Exact queries that select documents matching exact coordinates.
I’ve seen mobile applications that return lists or maps of entities located in the vicinity of my phone. For example, see Gas Buddy [http://gasbuddy.com/]. How would such applications work? I wanted to learn by doing. It seemed I needed spatial data and a way to query proximity to a location.
The book, MongoDB in Action, appendix E, addresses spatial queries. It provides a link to a zipped JSON array file suitable for importing Zip Code information [http://mng.bz/dOpd]. Each JSON array object looks like this:
{ "_id": "510dcc6b24b2186932ec4362", "city": "SPOKANE", "zip": "99205", "loc": { "y": 47.69641, "x": 117.439912 },"pop": 42032, "state": "WA"}This object is a document having city, state, zip, zip population, and x-y coordinates. The y is latitude; the x is longitude. Each _id is unique – the database primary key. The file was ready for importing into MongoDB.
I installed MongoDB MongoDB using instructions from their site [http://www.mongodb.org/]. MongoDB has a command-based admin and query console, mongo. There, I created database geospatial. I ran the mongoimport command to populate the database:
$ mongoimport -d geospatial -c zips zips.json
Returning to mongo, I issued:
use geospatial; db.zips.find();
A “find” argument is a JSON match document. An empty find argument yields a paged console dump of all documents, each formatted like the example JSON document seen earlier. I wanted to query records near a given longitude and latitude. I needed a 2d spatial index on the zips collection. I referred to the MongoDB in Action Manning book and the MongoDB Manual to see how to create a geo-spatial 2d index using the following incantation:
db.zips.ensureIndex( { loc : "2d" } )This gave my zips collection the brains to respond to proximity queries against a supplied latitude and longitude. MongodDB carries out the magic. The MongoDB proximity query meta-key is $near. I wanted zips collection documents $near a loc that is defined as a latitude / longitude (i.e. y/x) object within each document. For example:
db.zips.find( { 'loc': {$near : [ 47.6, 117.45] } } ).limit(3)This dumped three JSON documents containing Zip Codes nearest the coordinates of my hometown:
{ "_id" : ObjectId("510dcc6b24b2186932ec4361"), "city" : "SPOKANE", "zip" : "99204", "loc" : { "y" : 47.640682, "x" : 117.471896 }, "pop" : 24611, "state" : "WA" }
{ "_id" : ObjectId("510dcc6b24b2186932ec4360"), "city" : "SPOKANE", "zip" : "99203", "loc" : { "y" : 47.629443, "x" : 117.404121 }, "pop" : 20454, "state" : "WA" }
{ "_id" : ObjectId("510dcc6b24b2186932ec435e"), "city" : "SPOKANE", "zip" : "99201", "loc" : { "y" : 47.666485, "x" : 117.436527 }, "pop" : 9599, "state" : "WA" }Notice that the query input is a JSON document. That $near operator is a MongoDB geo-spatial feature. The limit(3) is a filtering API call.
Geo-spatial REST service
Cool! Next I needed a read-only REST service that could return a list of records matching a wildcard partial city query. A user could send one of those result document fields to another REST target that would return a list of $near records from which I’d get each Zip Code. I could use the mongo console to test the two queries.
I used Node.js as an HTTP server because its MongoDB language binding provides full-featured REST routing … and because I wanted to kick the tires of Node.js if possible. That’s for another blog article.
The Red Hat OpenShift platform-as-service (PaaS) cloud gave me a free place to put my service. It has a suite of “cartridges” from which to choose. These included MongoDB and Node.js. OpenShift has Git-based deployment along with an SSH shell within which I could run the mongo shell. I imported the database into a MongoDB instance resident in my wisp of the cloud. I wrote a simple Node.js REST service based on three MongoDB queries. I deployed it to OpenShift by using Git commands.
At this stage I could test my REST services with a browser or a curl command. Example URLs follow. Click them to see JSON results.
- A list of cities with names containing KANS … https://geospatial-mauget.rhcloud.com/cities/KANS
- A list of locations near zip code 27516 … https://geospatial-mauget.rhcloud.com/near/zip/27516
- … that redirects to a list of locations near the latitude/longitude of zip code 27516… https://geospatial-mauget.rhcloud.com/near/lat/35.579952/lon/78.790807
Mobile geo-spatial application
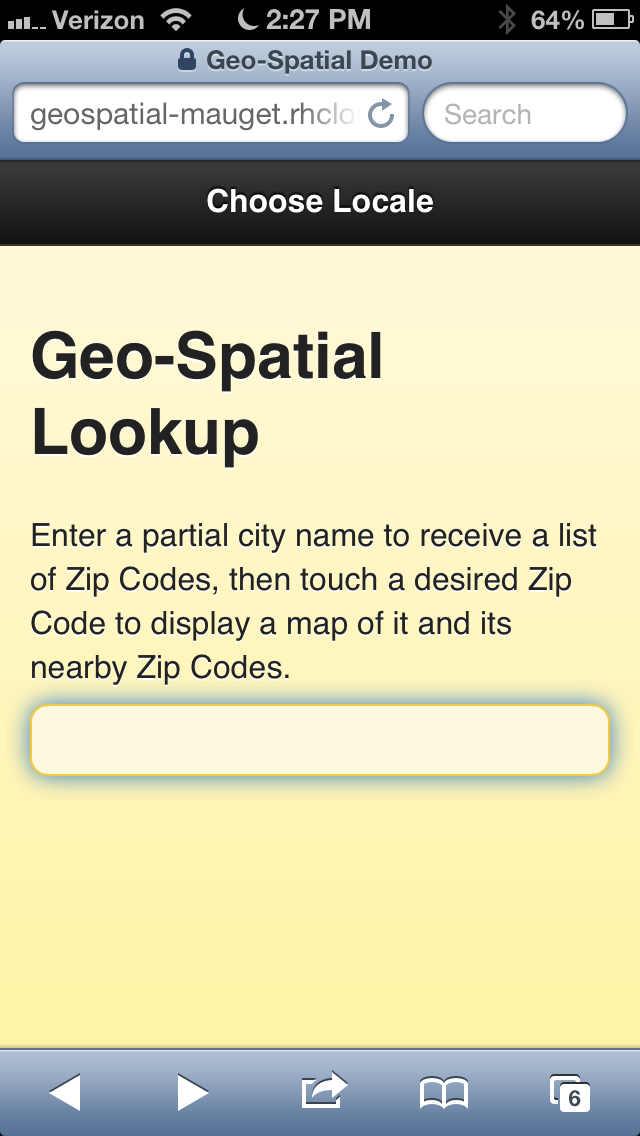
My REST service needed a client. I gave my Node.js server an additional route that simply returns a cached static index.html page. This page contains a single-page jQuery-Mobile client for the service. The physical page encompasses controller and view implemented as HTML5, CSS, and jQuery Mobile JavaScript for this simple application.
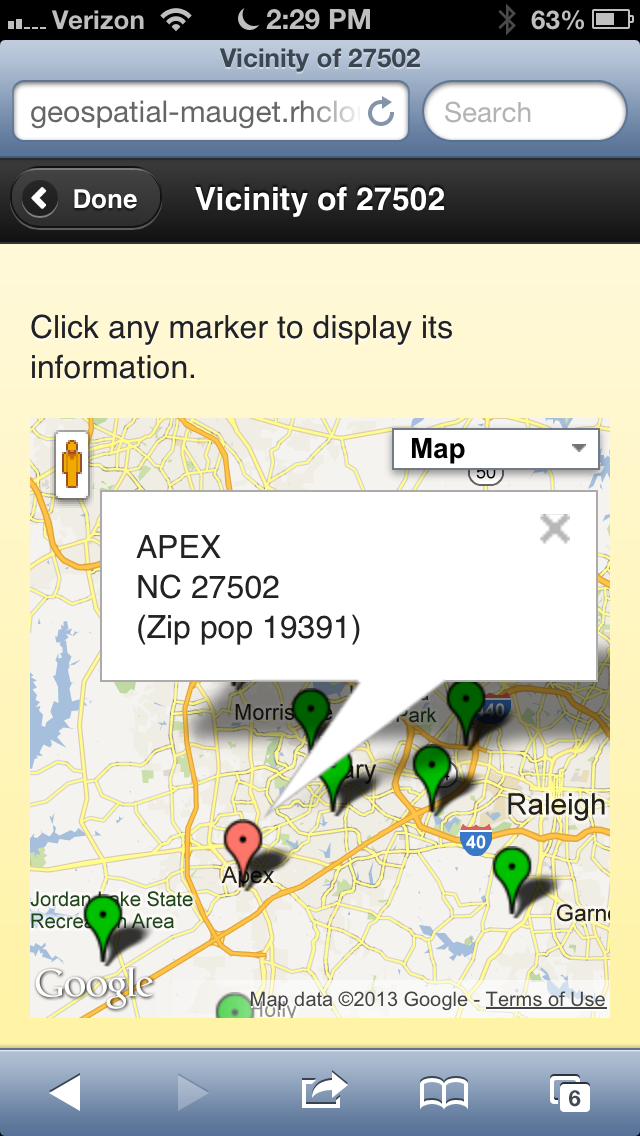
The page carries out AJAX REST calls based on user touches. Then it renders the returned JSON. The first logical page fronts a type-ahead search targeting query number one above. See Figure 1, and Figure 2. Each user input character causes a round-trip query to MongoDB, displaying a list of locations. Touch any search result row to render the second logical page. Refer to Figure 3. It uses query two to ask for the latitude/longitude of the given zip code. That query always causes a redirect to query three to obtain the list of $near results for the latitude/longitude. I used a redirect at the server instead of adding code to the client to issue query 3. Thus the client requests and receives a list of nearby zip codes to a city without ever dealing with latitude/longitude.
The request-response cycle leaves MongoDB at this point. The service redirects to Google Maps to render those $near results on a map. Each map pin is a zip code nearest the chosen zip code. A touch of a pin pops information about that zip code. Google and some JavaScript carry out this post-Mongo-stage magic.

You can clone or download an archive of the source at GitHub: https://github.com/mauget/geospatial-mongodb. Choices of repository clone or Zip file download are at the lower right of that page. You will need your own Google Maps API key or your copy will not operate with Google Maps.
You can try my deployment at https://geospatial-mauget.rhcloud.com/. Its layout is static, so it looks better in a phone. For a fake phone, try http://iphone5simulator.com/. Hats off to Red Hat for providing the “you-get-three-apps-free” OpenShift PaaS cloud service that hosts this demo without putting it to sleep after an hour of disuse.
What good is it?
This application is a demo. Consider, however, that you could morph the location collection into a finer-grained business address collection instead of a coarse collection of zip codes and zip code populations. Each business could register a document having the GPS latitude/longitude of its street address along with business information. The document could represent a gas station, a piece of real estate, a restaurant, a park, a weather map, a restaurant and its cuisine … whatever a useful application wants to present geographically near a point on Earth. Some business documents could have distinct attributes, such as a cuisine type if a restaurant. There is no schema, so it’s up to the application to handle route attributes or ignore them.
The application could query for locations nearby. The response action would render a geographic map of those addresses with a pin for each. Another view could be a list of locations ordered by distance or alphabetically. Touch a pin or a list item to see a drill-down into its information. A nightly job could live-update the business data without interference. Eventual consistency is friendly toward this kind of update.
Why MongoDB? Relational DBMS have spatial APIs, including Oracle and DB2. Please reread the characteristics of MongoDB at the top of this article. It appears that MongoDB is suitable for big responsive data. A distributed relational DBMS will eventually hit the wall in managing transactions across replicas while trying to scale past some point. We don’t care about transactions for this kind of application. Eventual consistency is an acceptable trade-off if we receive easily extended horizontal and vertical scaling in return. There are phones and tablets numbering like grains of sand out there that could pull from this kind of application.
– Lou Mauget, asktheteam@keyholesoftware.com
References:
- Wikipedia article: http://en.wikipedia.org/wiki/MongoDB
- MongoDB Manual: http://docs.mongodb.org/manual/
- 2d MongoDb Indexes: http://docs.mongodb.org/manual/core/geospatial-indexes/
- MongoDB in Action, auth. Kyle Banker, pub. Manning, © 2012, ISBN 9781935182870
- OpenShift: https://www.openshift.com/
- Node.js: http://nodejs.org/
- JQuery Mobile: http://jquerymobile.com/
- Git commands: http://git-scm.com/docs
- GitHub help: https://help.github.com/
- Is NoSql The SQL Sequel?: http://keyholesoftware.com/2012/10/01/is-nosql-the-sql-sequel/

