G1: Garbage First
The G1 collector is the latest collector to be implemented in the hotspot JVM. Its been a supported collector ever since Java 7 Update 4. Its also been publicly stated by the Oracle GC Team that their hope for low pause GC is a fully realised G1. This post follows on from my previous garbage collection blog posts:
The Problem: Large heaps mean Large Pause Times
The Concurrent Mark and Sweep (CMS) collector is the currently recommended low pause collector, but unfortunately its pause times scale with the amount of live objects in its tenured region. This means that whilst its relatively easy to get short GC Pauses with smaller heaps, but once you start using heaps in the 10s or 100s of Gigabytes the times start to ramp up.
CMS also doesn’t “defrag” its heap so at some point in time you’ll get a concurrent mode failure (CMF), triggering a full gc. Once you get into this full gc scenario you can expect a pause in the timeframe of roughly 1 second per Gigabyte of live objects. With CMS your 100GB heap can be a 1.5 minute GC Pause ticking time bomb waiting to happen …

Good GC Tuning can address this problem, but sometimes it just pushes the problem down the road. A Concurrent Mode Failure and therefore a Full GC is inevitable on a long enough timeline unless you’re in the tiny niche of people who deliberately avoid filling their tenured space.
G1 Heap Layout
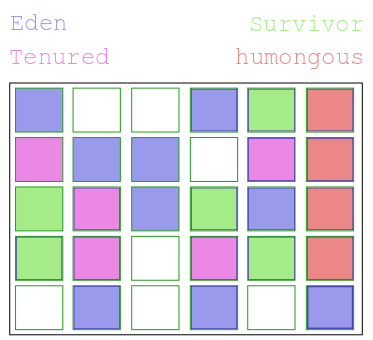
The G1 Collector tries to separate the pause time of an individual collection from the overall size of the heap by splitting up the heap into different regions. Each region is of a fixed size, between 1MB and 32MB, and the JVM aims to create about 2000 regions in total.

You may recall from previous articles that the other collectors split the heap up into Eden, Survior Space and Tenured memory pools. G1 retains the same categories of pools but instead of these being contiguous blocks of memory, each region is logically categorised into one of these pools.
There is also another type of region – the humongous region. These are designed to store objects which are bigger in size than most objects – for example a very long array. Any object which is bigger than 50% of the size of a region is stored in a humongous region. They work by taking multiple normal regions which are contiguously located in memory and treating them as a single logical region.
Remembered Sets
Of course there’s little point in splitting the heap into regions if you are going to have to scan the entire heap to figure out which objects are marked live. The first step in achieving this is breaking down regions into 512 Byte segments called cards. Each card has a 1 byte entry in the card marking table.
Each region has an associated remembered set or RSet – which is the set of cards that have been written to. A card is in the remembered set if an object from another region stored within the card points to an object within this region.
Whenever the mutator writes to an object reference, a write barrier is used to update the remembered set. Under the hood the remembered set is split up into different collections so that different threads can operate without contention, but conceptually all collections are part of the same remembered set.
Concurrent Marking
In order to identify which heap objects are live G1 performs a mostly concurrent mark of live objects.
- Marking Phase The goal of the marking phase is to figure out which objects within the heap are live. In order to store which objects are live, G1 uses a marking bitmap – which stores a single bit for every 64bits on the heap. All objects are traced from their roots, marking areas with live objects in the marking bitmap. This is mostly concurrent, but there is an Initial Marking Pause similar to CMS where the application is paused and the first level of children from the root objects are traced. After this completes the mutator threads restart. G1 needs to keep an up to date understanding of what is live in the heap, since the heap isn’t being cleaned up in the same pause as the marking phase.
- Remarking Phase The goal of the remarking phase is to bring the information from the marking phase about live objects up to date. The first thing to do is decide when to remark. Its triggered by a percentage of the heap being full. This is calculated by taking information from the marking phase and the number of allocations since then and which tells G1 whether its over the required percentage. G1 uses the aforementioned write barrier to take note of changes to the heap and store them in series of change buffers. The objects in the change buffer are marked in the marking bitmap concurrently. When the fill percentage is reached the mutator threads are paused again and the change buffers are processed, marking objects in change buffers live.
- Cleanup Phase At this point G1 knows which objects are live. Since G1 focusses on regions which have the most free space available, its next step is to work out the free space in a given region by counting the live objects. This is calculated from the marking bitmap, and regions are sorted according to which regions are most likely to be beneficial to collect. Regions which are to be collected are stored in what’s know as a collection set or CSet.
Evacuation
Similar to the approach taken by the hemispheric Young Generation in the Parallel GC and CMS collectors dead objects aren’t collected. Instead live objects get evacuated from a region and the entire region is then considered free.
G1 is intelligent about how it reclaims living objects – it doesn’t try to reclaim all living objects in a given cycle. It targets regions which are likely to reclaim as much space as possible and only evacuates those. It works out its target regions by calculating the proportion of live objects within a region and picking region with the lowest proportion of live objects.
Objects are evacuated into free regions, from multiple other regions. This means that G1 compacts the data when performing GC. This is operated on in parallel by multiple threads. The traditional ‘Parallel GC’ does this but CMS doesn’t.
Similar to CMS and Parallel GC there is a concept of tenuring. That is to say that young objects become ‘old’ if they survive enough collections. This number is called the tenuring threshold. If a young generational region survives the tenuring threshold and retains enough live objects to avoid being evacuated then the region is promoted. First to be a survivor and eventually a tenured region. It is never evacuated.
Evacuation Failure
Unfortunately, G1 can still encounter a scenario similar to a Concurrent Mode Failure in which it falls back to a Stop the World Full GC. This is called an evacuation failure and happens when there aren’t any regions which are free. No free regions means no where to evacuate objects.
Theoretically evacuation failures are less likely to happen in G1 than Concurrent Mode Failures are in CMS. This is because G1 compacts its regions on the fly rather than just waiting for a failure for compaction to occur.
Conclusions
Despite the compaction and efforts at low pauses G1 isn’t a guaranteed win and any attempt to adopt it should be accompanied by objective and measurable performance targets and GC Log analysis. The methodology required is out of the scope of this blog post, but hopefully I will cover it in a future post.
Algorithmically there are overheads that G1 encounters that other Hotspot collectors don’t. Notably the cost of maintaining remembered sets. Parallel GC is still the recommended throughput collector, and in many circumstances CMS copes better than G1.
Its too early to tell if G1 will be a big win over the CMS Collector, but in some situations its already providing benefits for developers who use it. Over time we’ll see if the performance limitations of G1 are really G1 limits or whether the development team just needs more engineering effort to solve the problems that are there.
Thanks to John Oliver, Tim Monks and Martijn Verburg for reviewing drafts of this and previous GC articles.

Thanks Richard..!!! Its Very helpful.
I found something useful on the same topic here.