This is going to be another story sharing our recent experience with memory-related problems. The case is extracted from a recent customer support case, where we faced a badly behaving application repeadedly dying with OutOfMemoryError messages in production. After running the application with Plumbr attached we were sure we were not facing a memory leak this time. But something was still terribly wrong.
The symptoms were discovered by one of our experimental features monitoring the overhead on certain data structures. It gave us a signal pinpointing towards one particular location in the source code. In order to protect the privacy of the customer we have recreated the case using a synthetic sample, at the same time keeping it technically equivalent to the original problem. Feel free to download the source code.
We found ourselves staring at a set of objects loaded from an external source. The communication with the external system was implemented via XML interface. Which is not bad per se. But the fact that the integration implementation details were scattered across the system – the documents received were converted to XMLBean instances and then used across the system – was not maybe the wisest thing.
Essentially we were dealing with a lazily-loaded caching solution. The objects cached were Persons:
// Imports and methods removed to improve readability
public class Person {
private String id;
private Date dateOfBirth;
private String forename;
private String surname;
}Not too memory-consuming one might guess. But things start to look a bit more sour when we open up some more details. Namely the implementation of this data was anything like the simple class declaration above. Instead, the implementation used a model-generated data structure. Model used was similar to the following simplified XSD snippet:
<xs:schema targetNamespace="http://plumbr.eu" xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> <xs:element name="person"> <xs:complexType> <xs:sequence> <xs:element name="id" type="xs:string"/> <xs:element name="dateOfBirth" type="xs:dateTime"/> <xs:element name="forename" type="xs:string"/> <xs:element name="surname" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Using XMLBeans, the developer had generated the model used behind the scenes. Now lets add the fact that the cache was supposed to hold up to 1.3M instances of Persons and we have created a strong foundation to failure.
Running a bundled testcase gave us an indication that 1.3M instances of the XMLBean-based solution would consume approximately 1.5GB of heap. We thought we could do better.
First solution is obvious. Integration details should not cross system boundaries. So we changed the caching solution to the simple java.util.HashMap<Long, Person> solution. ID as the key and Person object as the value. Immediately we saw the memory consumption reduced to 214MB. But we were not satisfied yet.
As the key in the Map was essentially a number, we had all the reasons to use Trove Collections to further reduce the overhead. Quick change in the implementation and we had replaced our HashMap withTLongObjectHashMap<Person>. Heap consumption dropped to 143MB.
We definitely could have stopped there, but the engineering curiosity did not allow us to do so. We could not help to notice that the data used contained a redundant piece of information. Date Of Birth was actually encoded in the ID, so instead of duplicating it in additional field, we could easily calculate the birthday from the given ID.
So we changed the layout of the Person object and now it contained just the following fields:
// Imports and methods removed to improve readability
public class Person {
private long id;
private String forename;
private String surname;
}Re-running the tests confirmed our expectations. Heap consumption was down to 93MB. But we were still not satisfied.
The application was running on 64-bit machine with an old JDK6 release. Which did not compress the ordinary object pointers by default. Switching to the -XX:+UseCompressedOops gave us an additional win – now we were down to 73MB consumed.
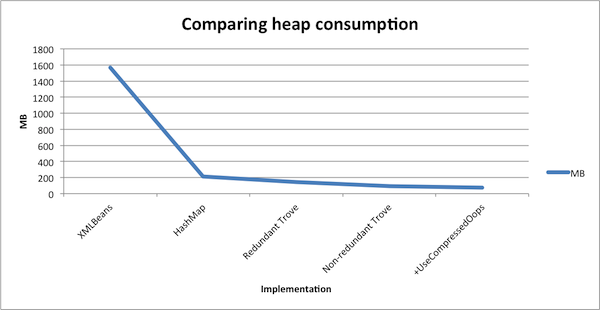
We could go further and start interning strings or building a b-tree based on the keys, but this would already start impacting the readability of the code, so we decided to stop here. 21.5x heap reduction should already be good enough result.
Lessons learned?
- Do not let integration details cross system boundaries
- Redundant data will be costly. Remove the redundancy whenever you can.
- Primitives are your friends. Know thy tools and learn Trove if you already haven’t
- Be aware of the optimization techniques provided by your JVM
If you are curious about the experiment conducted, feel free to download the code used from here. The utility used for measurements is described and available in this blogpost.

Thanks for sharing. That’s one hell of a bit of optimisation. Proves the mantra ‘Make it work then make it fast’ :)
That’s exactly what isn’t proved. Firstly the article is specifically about reducing menory consumption.
Secondly it mentions nothing about how fast the code before or after any of the changes.
“So we changed the caching solution to the simple java.util.HashMap solution” — it’s not clear what the previous solution was.
I’m also not sure what XMLBeans have to do with caching?
+1
Sound that caching technique was changed, but what is the actual improvement? In other words: what is the root cause of XMLBeans consuming so much memory?
why one uses XMLBeans for Caching?