I am investigating a memory issue in one of my recent projects where data is kept in memory for fast access, but the memory footprint of application is very high.
This application was heavily using CHM(i.e Concurrenthashmap), so no brainier guess was required that CHM was the issue. I did a memory profiling session to find how much memory CHM was really taking.
I was surprised with the result, CHM was taking around 50% of the memory. So it was confirmed that CHM was the issue, it is fast but not memory efficient.
Why CHM is so fat ?
- Key/Values are wrapped by Map.Entry objects, this creates an extra object per object.
- Each segment is a Re-entrant lock, so if you have lot of small CHM and concurrency level is default, then there will be lot of lock object and that will come in top list.
- and many more states for house keeping activities.
All of the above objects make a very good contribution to memory consumption.
How can we reduce memory footprint
If is difficult to reduce memory footprint of CHM and some possible reasons that I can think of are
- It has to support the old interface of Map
- The hash code collision technique used by java map is closed hashing. Closed hashing is based on creating Linklist on collision, closed hashing is very fast for resolution, but it is not CPU cache friendly, especially if nodes turns in big link list. There is interesting article about the LinkList problem
So we need an alternate CHM implementation which is memory efficient.
Version 2 of CHM
I started to create a version of CHM which has low memory foot print, the target is to come as close as an array. I also used alternate hash code collision techniques to check the performance, there are many options for Open_addressing
I tried the options below:
- Linear probing – performance was not that great, although this is the most CPU cache friendly. Need to spend some more time to get it right.
- Double_hashing – Performance was in acceptable range.
Lets measure CHM V2
- Memory footprint
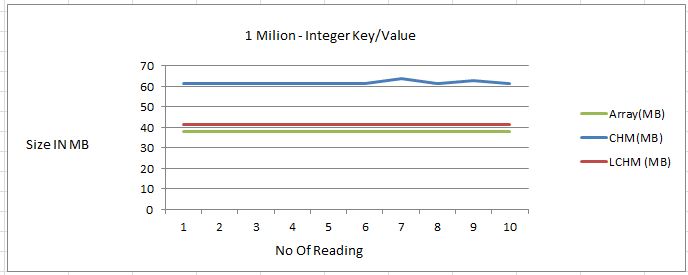
There is a big gain in terms of memory, CHM takes around 45%+ more than raw data, new implementation LCHM is very much close to Array type.
- Single thread PUT performance
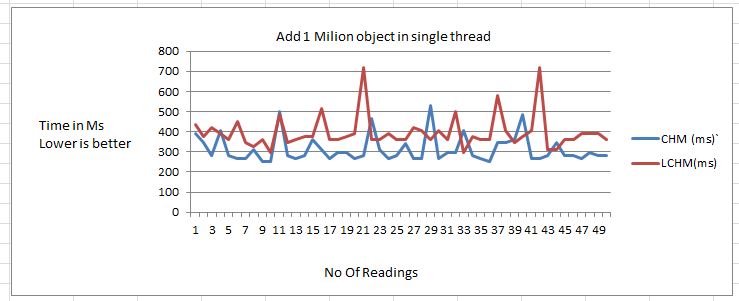
CHM outperforms in PUT test, new implementation is around 50 to 80 Millisecond slower for 1 Million items. 50 to 80 ms is not a noticeable delay and I think it is good for applications where latency requirement is in seconds. In case that the latency requirement is in millisecond/nanosecond, then any way CHM will not be a good choice. The reason for slow performance of LCHM is hash collision technique, double hashing is used for resolving has code collision.
- Concurrent Add performance
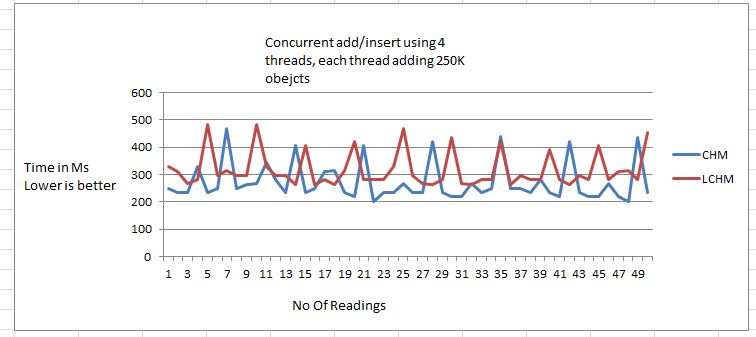
New implementation performs slightly better when multiple threads are used to write to map.
- Get Performance
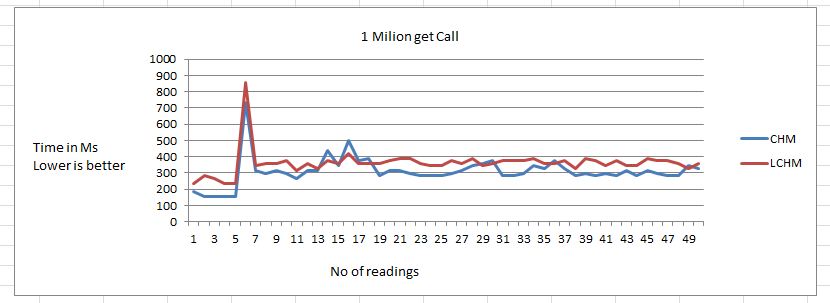
Performance of GET is slightly slower as compared to CHM.
Conclusion
New implementation outperforms in memory test and it is a bit slow in get/put test. There are a couple of things that can be done to improve performance of get/put and all the performance difference that we see is due to probing technique used.
- Probing technique can be improved, linear probing technique can used to to get cache friendly access.
- It is very easy to make probing technique parallel.
