Reduce Side Join
Let’s take the following tables containing employee and department data.
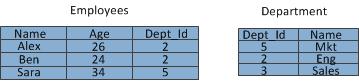
Let’s see how join query below can be achieved using reduce side join.
SELECT Employees.Name, Employees.Age, Department.Name FROM Employees INNER JOIN Department ON Employees.Dept_Id=Department.Dept_Id
Map side is responsible for emitting the join predicate values along with the corresponding record from each table so that records having same department id in both tables will end up at on same reducer which would then do the joining of records having same department id. However it is also required to tag the each record to indicate from which table the record originated so that joining happens between records of two tables. Following diagram illustrates the reduce side join process.

Here is the pseudo code for map function for this scenario.
map (K table, V rec) {
dept_id = rec.Dept_Id
tagged_rec.tag = table
tagged_rec.rec = rec
emit(dept_id, tagged_rec)
}
At reduce side join happens within records having different tags.
reduce (K dept_id, list<tagged_rec> tagged_recs) {
for (tagged_rec : tagged_recs) {
for (tagged_rec1 : taagged_recs) {
if (tagged_rec.tag != tagged_rec1.tag) {
joined_rec = join(tagged_rec, tagged_rec1)
}
emit (tagged_rec.rec.Dept_Id, joined_rec)
}
}
Map Side Join (Replicated Join)
Using Distributed Cache on Smaller Table
For this implementation to work one relation has to fit in to memory. The smaller table is replicated to each node and loaded to the memory. The join happens at map side without reducer involvement which significantly speeds up the process since this avoids shuffling all data across the network even though most of the records not matching are later dropped. Smaller table can be populated to a hash-table so look-up by Dept_Id can be done. The pseudo code is outlined below.
map (K table, V rec) {
list recs = lookup(rec.Dept_Id) // Get smaller table records having this Dept_Id
for (small_table_rec : recs) {
joined_rec = join (small_table_rec, rec)
}
emit (rec.Dept_id, joined_rec)
}
Using Distributed Cache on Filtered Table
If the smaller table doesn’t fit the memory it may be possible to prune the contents of it if filtering expression has been specified in the query. Consider following query.
SELECT Employees.Name, Employees.Age, Department.Name FROM Employees INNER JOIN Department ON Employees.Dept_Id=Department.Dept_Id WHERE Department.Name="Eng"
Here a smaller data set can be derived from Department table by filtering out records having department names other than “Eng”. Now it may be possible to do replicated map side join with this smaller data set.
Replicated Semi-Join
Reduce Side Join with Map Side Filtering
Even of the filtered data of small table doesn’t fit in to the memory it may be possible to include just the Dept_Id s of filtered records in the replicated data set. Then at map side this cache can be used to filter out records which would be sent over to reduce side thus reducing the amount of data moved between the mappers and reducers.
The map side logic would look as follows.
map (K table, V rec) {
// Check if this record needs to be sent to reducer
boolean sendToReducer = check_cache(rec.Dept_Id)
if (sendToReducer) {
dept_id = rec.Dept_Id
tagged_rec.tag = table
tagged_rec.rec = rec
emit(dept_id, tagged_rec)
}
}
Reducer side logic would be same as the Reduce Side Join case.
Using a Bloom Filter
A bloom filter is a construct which can be used to test the containment of a given element in a set. A smaller representation of filtered Dept_ids can be derived if Dept_Id values can be augmented in to a bloom filter. Then this bloom filter can be replicated to each node. At the map side for each record fetched from the smaller table the bloom filter can be used to check whether the Dept_Id in the record is present in the bloom filter and only if so to emit that particular record to reduce side. Since a bloom filter is guaranteed not to provide false negatives the result would be accurate.
Reference: Joins with Map Reduce from our JCG partner Buddhika Chamith at the Source Open blog.
