Since these file channels work asynchronously, it is interesting to look at their performance compared to conventional I/O. The second part deals with issues like memory and CPU consumption and explains how to use the new NIO.2 channels safely in a high performance scenario. You also need to understand how to close asynchronous channels without loosing data, that’s part three. Finally, in part four, we’ll take a look into concurrency.
Notice: I won’t explain the complete API of asynchronous file channels. There are enough posts out there that do a good job on that. My posts dive more into practical applicability and issues you may have when using asynchronous file channels.
OK, enough vague talking, let’s get started. Here is a code snippet that opens an asynchronous channel (line 7), writes a sequence of bytes to the beginning of the file (line 9) and waits for the result to return (line 10). Finally, in line 14 the channel is closed.
public class CallGraph_Default_AsynchronousFileChannel {
private static AsynchronousFileChannel fileChannel;
public static void main(String[] args) throws InterruptedException, IOException, ExecutionException {
try {
fileChannel = AsynchronousFileChannel.open(Paths.get("E:/temp/afile.out"), StandardOpenOption.READ,
StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.DELETE_ON_CLOSE);
Future<Integer> future = fileChannel.write(ByteBuffer.wrap("Hello".getBytes()), 0L);
future.get();
} catch (Exception e) {
e.printStackTrace();
} finally {
fileChannel.close();
}
}
}
Important participants in asynchonous file channel calls
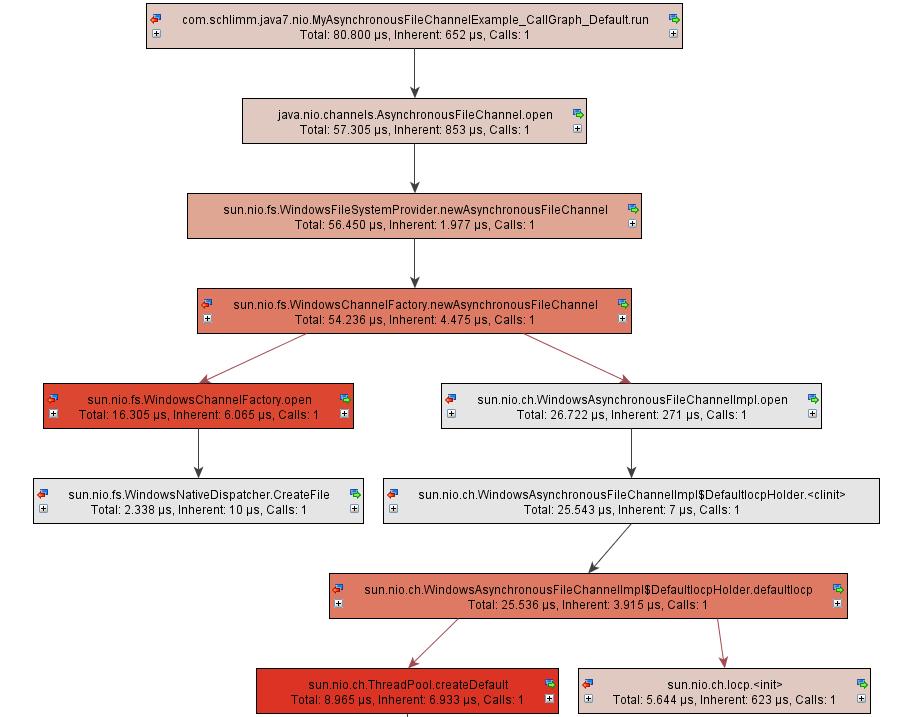
Before I continue to dive into the code, let’s introduce quickly the involved concepts in the asynchronous (file) channel galaxy. The callgraph in figure 1 shows the sequence diagram in a call to the open()-method of the AsynchronousFileChannel class. A FileSystemProvider encapsulates all the operating systems specifics. To amuse everybody I am using a Windows XP client when I am writing this. Therefeore a WindowsFileSystemProvider calls the WindowsChannelFactory which actually creates the file and calls the WindowsAsynchronousFileChannelImpl which returns an instance of itself. The most important concept is the Iocp, the I/O completion port. It is an API for performing multiple simultaneous asynchronous input/output operations. A completion port object is created and associated with a number of file handles. When I/O services are requested on the object, completion is indicated by a message queued to the I/O completion port. Other processes requesting I/O services are not notified of completion of the I/O services, but instead check the I/O completion port’s message queue to determine the status of its I/O requests. The I/O completion port manages multiple threads and their concurrency. Is you can see from the diagram the Iocp is a subtype of AsynchronousChannelGroup. So in JDK 7 asynchronous channels the asynchronous channel group is implemented as an I/O completion port. It owns the ThreadPool responsible for performing the requested asynchronous I/O operation. The ThreadPool actually encapsulates a ThreadPoolExecutor that does all the multi-threaded asynchronous task execution management since Java 1.5. Write operations to asnchronous file channels result in calls to the ThreadPoolExecutor.execute() method.
Some benchmarks
It’s always interesting to look at the performance. Asynchronous non blocking I/O must be fast, right? To find an answer to that question I have made my benchmark analysis. Again, I am using Heinz’ tiny benchmarking framework to do that. My machine is an Intel Core i5-2310 CPU @ 2.90 GHz with four cores (64-bit). In a benchmark I need a baseline. My baseline is a simple conventional synchronous write operation into an ordinary file. Here is the snippet:
public class Performance_Benchmark_ConventionalFileAccessExample_1 implements Runnable {
private static FileOutputStream outputfile;
private static byte[] content = "Hello".getBytes();
public static void main(String[] args) throws InterruptedException, IOException {
try {
System.out.println("Test: " + Performance_Benchmark_ConventionalFileAccessExample_1.class.getSimpleName());
outputfile = new FileOutputStream(new File("E:/temp/afile.out"), true);
Average average = new PerformanceHarness().calculatePerf(new PerformanceChecker(1000, new Performance_Benchmark_ConventionalFileAccessExample_1()), 5);
System.out.println("Mean: " + DecimalFormat.getInstance().format(average.mean()));
System.out.println("Std. Deviation: " + DecimalFormat.getInstance().format(average.stddev()));
} catch (Exception e) {
e.printStackTrace();
} finally {
new SystemInformation().printThreadInfo(true);
outputfile.close();
new File("E:/temp/afile.out").delete();
}
}
@Override
public void run() {
try {
outputfile.write(content); // append content
} catch (IOException e) {
e.printStackTrace();
}
}
}
As you can see in line 25, the benchmark performs a single write operation into an ordinary file. And these are the results:
Test: Performance_Benchmark_ConventionalFileAccessExample_1 Warming up ... EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:365947 EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:372298 Starting test intervall ... EPSILON:20:TESTTIME:1000:ACTTIME:1000:LOOPS:364706 EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:368309 EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:370288 EPSILON:20:TESTTIME:1000:ACTTIME:1001:LOOPS:364908 EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:370820 Mean: 367.806,2 Std. Deviation: 2.588,665 Total started thread count: 12 Peak thread count: 6 Deamon thread count: 4 Thread count: 5
The following snippet is another benchmark which also issues a write operation (line 25), this time to an asynchronous file channel:
public class Performance_Benchmark_AsynchronousFileChannel_1 implements Runnable {
private static AsynchronousFileChannel outputfile;
private static int fileindex = 0;
public static void main(String[] args) throws InterruptedException, IOException {
try {
System.out.println("Test: " + Performance_Benchmark_AsynchronousFileChannel_1.class.getSimpleName());
outputfile = AsynchronousFileChannel.open(Paths.get("E:/temp/afile.out"), StandardOpenOption.WRITE,
StandardOpenOption.CREATE, StandardOpenOption.DELETE_ON_CLOSE);
Average average = new PerformanceHarness().calculatePerf(new PerformanceChecker(1000,
new Performance_Benchmark_AsynchronousFileChannel_1()), 5);
System.out.println("Mean: " + DecimalFormat.getInstance().format(average.mean()));
System.out.println("Std. Deviation: " + DecimalFormat.getInstance().format(average.stddev()));
} catch (Exception e) {
e.printStackTrace();
} finally {
new SystemInformation().printThreadInfo(true);
outputfile.close();
}
}
@Override
public void run() {
outputfile.write(ByteBuffer.wrap("Hello".getBytes()), fileindex++ * 5);
}
}
This is the result of the above benchmark on my machine:
Test: Performance_Benchmark_AsynchronousFileChannel_1 Warming up ... EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:42667 EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:193351 Starting test intervall ... EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:191268 EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:186916 EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:189842 EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:191103 EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:192005 Mean: 190.226,8 Std. Deviation: 1.795,733 Total started thread count: 17 Peak thread count: 11 Deamon thread count: 9 Thread count: 10
Since the snippets above do the same thing, it’s safe to say that asynchronous files channels aren’t necessarily faster then conventional I/O. That’s an interesting result I think. It’s difficult to compare conventional I/O and NIO.2 to each other in a single threaded benchmark. NIO.2 was introduced to provide an I/O technique in highly concurrent scenarios. Therefore asking what’s faster – NIO or conventional I/O – isn’t quite the right question. The appropriate question was: what is “more concurrent”? However, for now, the results above suggest:
Consider using conventional I/O when only one thread is issueing I/O-operations.
That’s enough for now. I have explained the basic concepts and also pointed out that conventional I/O still has its right to exist. In the second post I will introduce some of the issues you may encounter when you use default asynchronous file channels. I will also show how to avoid those issues by applying some more viable settings.
Applying custom thread pools
Asynchronous file processing isn’t a green card for high performance. In my last post I have demonstrated that conventional I/O can be faster then asynchronous channels. There are some additional important facts to know when applying NIO.2 file channels. The Iocp class that performs all the asynchronous I/O tasks in NIO.2 file channels is, by default, backed by a so called “cached” thread pool. That’s a thread pool that creates new threads as needed, but will reuse previously constructed threads *when* they are available. Look at the code of the ThreadPool class held by the Iocp.
public class ThreadPool {
...
private static final ThreadFactory defaultThreadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
return t;
}
};
...
static ThreadPool createDefault() {
...
ExecutorService executor =
new ThreadPoolExecutor(0, Integer.MAX_VALUE,
Long.MAX_VALUE, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
return new ThreadPool(executor, false, initialSize);
}
...
}
The thread pool in the default channel group is constructed as ThreadPoolExecutor with a maximum thread count of Integer.MAX_VALUE and a keep-alive-time of Long.MAX_VALUE. The threads are created as daemon threads by the thread factory. A synchronous hand-over queue is used to trigger thread creation if all threads are busy. There are several issues with this configuration:
- If you perform write operations on asynchronous channels in a burst you will create thousands of worker threads which likely results in an OutOfMemoryError: unable to create new native thread.
- When the JVM exits, then all deamon threads are abandoned – finally blocks are not executed, stacks are not unwound.
In my other blog I have explained why unbounded thread pools can ’cause trouble. Therefore, if you use asynchronous file channels, it may be an option to use custom thread pools instead of the default thread pool. The following snippet shows an example custom setting.
ThreadPoolExecutor pool = new
ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(2500));
pool.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
AsynchronousFileChannel outputfile =
AsynchronousFileChannel.open(Paths.get(FILE_NAME),
new HashSet<Standardopenoption>
(Arrays.asList(StandardOpenOption.WRITE, StandardOpenOption.CREATE)), pool);
The javadoc of AsynchronousFileChannel states that the custom executor should “minimally […] support an unbounded work queue and should not run tasks on the caller thread of the execute method.” That’s a risky statement, it is only reasonable if resources aren’t an issue, which is rarely the case. It may make sense to use bounded thread pools for asynchronous file channels. You cannot get a too-many-threads issue, also you cannot flood your heap with work queue tasks. In the example above you have five threads that execute asynchonous I/O tasks and the work queue has a capacity of 2500 tasks. If the capacity limit is exceeded the rejected-execution-handler implements the CallerRunsPolicy where the client has to execute the write task synchronously. This can (dramatically) slow down the system performance because the workload is “pushed back” to the client and executed synchronously. However, it can also save you from much more severe issues where the result is unpredictable. It’s a good practice to work with bounded thread pools and to keep the thread pool sizes configurable, so that you can adjust them at runtime. Again, to learn more about robust thread pool settings see my other blog entry.
Thread pools with synchronous hand-over queues and unbound maximum thread pool sizes can aggressively create new threads and thus can seriously harm system stability by consuming (pc registers and java stacks) runtime memory of the JVM. The ‘longer’ (elapsed time) the asynchronous task, the more likely you’ll run into this issue.
Thread pools with unbounded work queues and fixed thread pool sizes can aggressively create new tasks and objects and thus can seriously harm system stability by consuming heap memory and CPU through excessive garbage collection activity. The larger (in size) and longer (in elapsed time) the asynchronous task the more likely you’ll run into this issue.
That’s all in terms of applying custom thread pools to asynchronous file channels. My next blog in this series will explain how to close asynchronous channels safely without loosing data.
Reference: Java 7 #7: NIO.2 File Channels on the test bench – Part 1 – Introduction , Java 7 #8: NIO.2 File Channels on the test bench – Part 2 – Applying custom thread pools from our JCG partner Niklas.

Thanks, nice post