It is useful any time you need to evaluate expressions unknown at compile-time or to parse non-trivial user input or files in a weird format. Of course, it is possible to create custom hand made parser for any of these tasks. However, it usually takes much more time and effort. A little knowledge of a good parser generator may turn these time-consuming tasks into easy and fast exercises.
This post begins with a small demonstration of ANTLR usefulness. Then, we explain what ANTLR is and how does it work. Finally, we show how to compile a simple ‘Hello word!’ language into an abstract syntax tree. The post explains also how to add error handling and how to test the language.
Next post shows how to create a real expression language.
Real Word Examples
ANTLR seems to be popular in open source word. Among others, it is used by Apache Camel, Apache Lucene, Apache Hadoop, Groovy and Hibernate. They all needed parser for a custom language. For example, Hibernate uses ANTLR to parse its query language HQL.
All those are big frameworks and thus more likely to need domain specific language than small application. The list of smaller projects using ANTLR is available on its showcase list. We found also one stackoverflow discussion on the topic.
To see where ANTLR could be useful and how it could save time, try to estimate following requirements:
- Add formula calculator into an accounting system. It will calculate values of formulas such as
(10 + 80)*sales_tax. - Add extended search field into a recipe search engine. It will search for receipts matching expressions such as
(chicken and orange) or (no meat and carrot).
Our safe estimate is a day and half including documentation, tests, and integration into the project. ANTLR is worth looking at if you are facing similar requirements and made significantly higher estimate.
Overview
ANTLR is code generator. It takes so called grammar file as input and generates two classes: lexer and parser.
Lexer runs first and splits input into pieces called tokens. Each token represents more or less meaningful piece of input. The stream of tokes is passed to parser which do all necessary work. It is the parser who builds abstract syntax tree, interprets the code or translate it into some other form.
Grammar file contains everything ANTLR needs to generate correct lexer and parser. Whether it should generate java or python classes, whether parser generates abstract syntax tree, assembler code or directly interprets code and so on. As this tutorial shows how to build abstract syntax tree, we will ignore other options in following explanations.
Most importantly, grammar file describes how to split input into tokens and how to build tree from tokens. In other words, grammar file contains lexer rules and parser rules.
Each lexer rule describes one token:
TokenName: regular expression;
Parser rules are more complicated. The most basic version is similar as in lexer rule:
ParserRuleName: regular expression;
They may contain modifiers that specify special transformations on input, root and childs in result abstract syntax tree or actions to be performed whenever rule is used. Almost all work is usually done inside parser rules.
Infrastructure
First, we show tools to make development with ANTLR easier. Of course, nothing of what is described in this chapter is necessary. All examples work with maven, text-editor and internet connection only.
ANTLR project produced stand alone IDE, Eclipse plugin and Idea plugin. We did not found NetBeans plugin.
ANTLRWorks
Stand alone ide is called ANTLRWorks. Download it from the project download page. ANTLRWorks is a single jar file, use java -jar antlrworks-1.4.3.jar command to run it.
The IDE has more features and is more stable than Eclipse plugin.
Eclipse Plugin
Download and unpack ANTLR v3 from ANTLR download page. Then, install ANTLR plugin from Eclipse Marketplace:
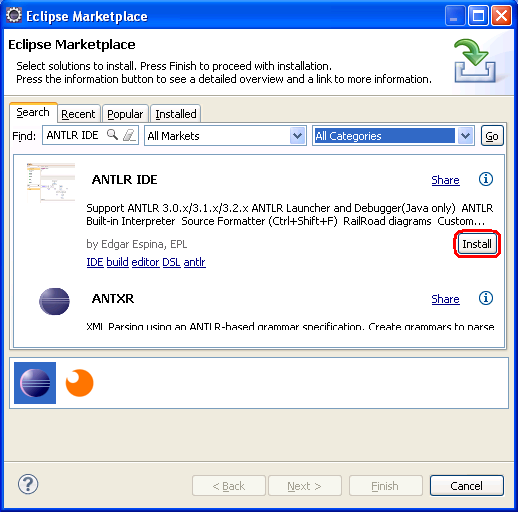
Go to Preferences and configure ANTLR v3 installation directory:
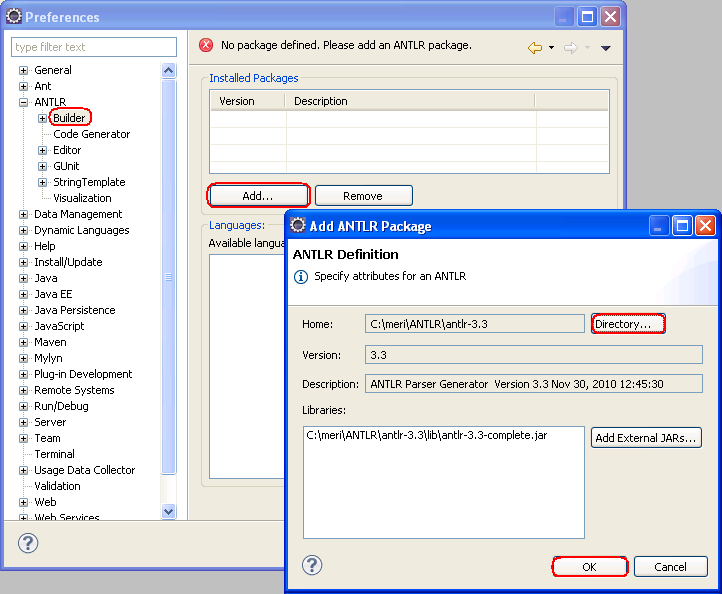
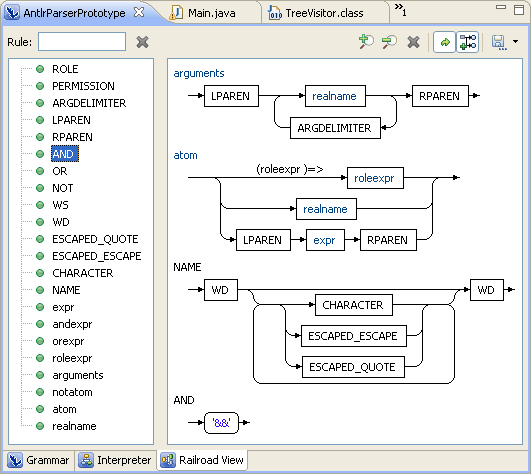
To test the configuration, download sample grammar file and open it in eclipse. It will be open it in ANTLR editor. The editor has three tabs:
- Grammar – text editor with syntax highlighting, code completion and so on.
- Interpreter – compiles test expressions into syntax trees, may produce different result than generated parser. It tend to throw failed predicate exception on correct expressions.
- Railroad View – paints nice graphs of your lexer and parser rules.
An Empty Project – Maven Configuration
This chapter shows how to add ANTLR into a maven project. If you use Eclipse and do not have a m2eclipse plugin installed yet, install it from http://download.eclipse.org/technology/m2e/releases update site. It will make your life much easier.
Create Project
Create new maven project and specify maven-archetype-quickstart on ‘Select an Archetype’ screen. If you do not use Eclipse, command mvn archetype:generate achieves the same.
Dependency
Add ANTLR dependency into pom.xml:
org.antlr
antlr
3.3
jar
compile
Note: As ANTLR does not have history of being backward-compatible, it is better to specify required version.
Plugins
Antlr maven plugin runs during generate-sources phase and generates both lexer and parser java classes from grammar (.g) files. Add it into pom.xml:
org.antlr
antlr3-maven-plugin
3.3
run antlr
generate-sources
antlr
Create src/main/antlr3 folder. The plugin expects all grammar files in there.
Generated files are put into target/generated-sources/antlr3 directory. As this directory is not in default maven build path, we use build-helper-maven-plugin to add it there:
org.codehaus.mojo
build-helper-maven-plugin
add-source
generate-sources
add-source
${basedir}/target/generated-sources/antlr3
If you use eclipse, you have to update project configuration: right click on the project -> ‘maven’ -> ‘Update Project Configuration’.
Test It
Invoke maven to test project configuration: right click on the project -> ‘Run As’ -> ‘Maven generate-sources’. Alternatively, use mvn generate-sources command.
Build should be successful. Console output should contain antlr3-maven-plugin plugin output:
[INFO] --- antlr3-maven-plugin:3.3:antlr (run antlr) @ antlr-step-by-step --- [INFO] ANTLR: Processing source directory C:\meri\ANTLR\workspace\antlr-step-by-step\src\main\antlr3 [INFO] No grammars to process ANTLR Parser Generator Version 3.3 Nov 30, 2010 12:46:29
It should be followed by build-helper-maven-plugin plugin output:
[INFO] --- build-helper-maven-plugin:1.7:add-source (add-source) @ antlr-step-by-step --- [INFO] Source directory: C:\meri\ANTLR\workspace\antlr-step-by-step\target\generated-sources\antlr3 added.
The result of this phase in located on github, tag 001-configured_antlr.
Hello Word
We will create simplest possible language parser – hello word parser. It builds a small abstract syntax tree from a single expression: ‘Hello word!’.
We will use it to show how to create a grammar file and generate ANTLR classes from it. Then, we will show how to use generated files and create an unit test.
First Grammar File
Antlr3-maven-plugin searches src/main/antlr3 directory for grammar files. It creates new package for each sub-directory with grammar and generates parser and lexer classes into it. As we wish to generate classes into org.meri.antlr_step_by_step.parsers package, we have to create src/main/antlr3/org/meri/antlr_step_by_step/parsers directory.
Grammar name and file name must be identical. File must have .g suffix. Moreover, each grammar file begins with a grammar name declaration. Our S001HelloWord grammar begins with following line:
grammar S001HelloWord;
eclaration is always followed by generator options. We are working on java project and wish to compile expressions into abstract syntax tree:
options {
// antlr will generate java lexer and parser
language = Java;
// generated parser should create abstract syntax tree
output = AST;
}
Antlr does not generate package declaration on top of generated classes. We have to use @parser::header and @lexer::header blocks to enforce it. Headers must follow options block:
@lexer::header {
package org.meri.antlr_step_by_step.parsers;
}
@parser::header {
package org.meri.antlr_step_by_step.parsers;
}
Each grammar file must have at least one lexer rule. Each lexer rule must begin with upper case letter. We have two rules, first defines a salutation token, second defines an endsymbol token. Salutation must be ‘Hello word’ and endsymbol must be ‘!’.
SALUTATION:'Hello word'; ENDSYMBOL:'!';
Similarly, each grammar file must have at least one parser rule. Each parser rule must begin with lower case letter. We have only one parser rule: any expression in our language must be composed of a salutation followed by an endsymbol.
expression : SALUTATION ENDSYMBOL;
Note: the order of grammar file elements is fixed. If you change it, antlr plugin will fail.
Generate Lexer and Parser
Generate a lexer and parser from command line using mvn generate-sources command or from Eclipse:
- Right click on the project.
- Click ‘Run As’.
- Click ‘Maven generate-sources’.
Antlr plugin will create target/generated-sources/antlr/org/meri/antlr_step_by_step/parsers folder and place S001HelloWordLexer.java and S001HelloWordParser.java files inside.
Use Lexer and Parser
Finally, we create compiler class. It has only one public method which:
- calls generated lexer to split input into tokens,
- calls generated parser to build AST from tokens,
- prints result AST tree into console,
- returns abstract syntax tree.
Compiler is located in S001HelloWordCompiler class:
public CommonTree compile(String expression) {
try {
//lexer splits input into tokens
ANTLRStringStream input = new ANTLRStringStream(expression);
TokenStream tokens = new CommonTokenStream( new S001HelloWordLexer( input ) );
//parser generates abstract syntax tree
S001HelloWordParser parser = new S001HelloWordParser(tokens);
S001HelloWordParser.expression_return ret = parser.expression();
//acquire parse result
CommonTree ast = (CommonTree) ret.tree;
printTree(ast);
return ast;
} catch (RecognitionException e) {
throw new IllegalStateException("Recognition exception is never thrown, only declared.");
}
Note: Do not worry about RecognitionException exception declared on S001HelloWordParser.expression() method. It is never thrown.
Testing It
We finish this chapter with a small test case for our new compiler. Create S001HelloWordTest class:
public class S001HelloWordTest {
/**
* Abstract syntax tree generated from "Hello word!" should have an
* unnamed root node with two children. First child corresponds to
* salutation token and second child corresponds to end symbol token.
*
* Token type constants are defined in generated S001HelloWordParser
* class.
*/
@Test
public void testCorrectExpression() {
//compile the expression
S001HelloWordCompiler compiler = new S001HelloWordCompiler();
CommonTree ast = compiler.compile("Hello word!");
CommonTree leftChild = ast.getChild(0);
CommonTree rightChild = ast.getChild(1);
//check ast structure
assertEquals(S001HelloWordParser.SALUTATION, leftChild.getType());
assertEquals(S001HelloWordParser.ENDSYMBOL, rightChild.getType());
}
}
The test will pass successfully. It will print abstract syntax tree to the console:
0 null -- 4 Hello word -- 5 !
Grammar in IDE
Open S001HelloWord.g in editor and go to interpreter tab.
- Highlight expression rule in top left view.
- Write ‘Hello word!’ into top right view.
- Press green arrow in top left corner.
Interpreter will generate parse tree:

Copy Grammar
Each new grammar in this tutorial is based on previous one. We compiled a list of steps needed to copy an old grammar into a new one. Use them to copy an OldGrammar into a NewGrammar:
- Copy OldGrammar.g to NewGrammar.g in the same directory.
- Change grammar declaration to
grammar NewGrammar; - Generate parser and lexer.
- Create new class NewGrammarCompiler analogous to previous OldGrammarCompiler class.
- Create new test class NewGrammarTest analogous to previous OldGrammarTest class.
No task is really finished without an appropriate error handling. Generated ANTLR classes try to recover from errors whenever possible. They do report errors to the console, but there is no out-of-the box API to programmatically find about syntax errors.
This could be fine if we would build command line only compiler. However, lets assume that we are building a GUI to our language, or use the result as input to another tool. In such case, we need an API access to all generated errors.
In the beginning of this chapter, we will experiment with default error handling and create test case for it. Then, we will add a naive error handling, which will throw an exception whenever first error happens. Finally, we will move to the ‘real’ solution. It will collect all errors in an internal list and provide methods to access them.
As a side product, the chapter shows how to:
- add custom catch clause to parser rules,
- add new methods and fields to generated classes,
- override generated methods.
Default Error Handling
First, we will try to parse various incorrect expressions. The goal is to understand default ANTLR error handling behavior. We will create test case from each experiment. All test cases are located in S001HelloWordExperimentsTest class.
Expression 1: Hello word?
Result tree is very similar to the correct one:
0 null -- 4 Hello word -- 5 ?<missing ENDSYMBOL>
Console output contains errors:
line 1:10 no viable alternative at character '?' line 1:11 missing ENDSYMBOL at '<eof>'
Test case: following test case passes with no problem. No exception is thrown and abstract syntax tree node types are the same as in correct expression.
@Test
public void testSmallError() {
//compile the expression
S001HelloWordCompiler compiler = new S001HelloWordCompiler();
CommonTree ast = compiler.compile("Hello word?");
//check AST structure
assertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType());
assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType());
}
Expression 2: Bye!
Result tree is very similar to the correct one:
0 null -- 4 <missing> -- 5 ! </missing>
Console output contains errors:
line 1:0 no viable alternative at character 'B' line 1:1 no viable alternative at character 'y' line 1:2 no viable alternative at character 'e' line 1:3 missing SALUTATION at '!'
Test case: following test case passes with no problem. No exception is thrown and abstract syntax tree node types are the same as in correct expression.
@Test
public void testBiggerError() {
//compile the expression
S001HelloWordCompiler compiler = new S001HelloWordCompiler();
CommonTree ast = compiler.compile("Bye!");
//check AST structure
assertEquals(S001HelloWordParser.SALUTATION, ast.getChild(0).getType());
assertEquals(S001HelloWordParser.ENDSYMBOL, ast.getChild(1).getType());
}
Expression 3: Incorrect Expression
Result tree has only root node with no childs:
0
Console output contains a lot of errors:
line 1:0 no viable alternative at character 'I' line 1:1 no viable alternative at character 'n' line 1:2 no viable alternative at character 'c' line 1:3 no viable alternative at character 'o' line 1:4 no viable alternative at character 'r' line 1:5 no viable alternative at character 'r' line 1:6 no viable alternative at character 'e' line 1:7 no viable alternative at character 'c' line 1:8 no viable alternative at character 't' line 1:9 no viable alternative at character ' ' line 1:10 no viable alternative at character 'E' line 1:11 no viable alternative at character 'x' line 1:12 no viable alternative at character 'p' line 1:13 no viable alternative at character 'r' line 1:14 no viable alternative at character 'e' line 1:15 no viable alternative at character 's' line 1:16 no viable alternative at character 's' line 1:17 no viable alternative at character 'i' line 1:18 no viable alternative at character 'o' line 1:19 no viable alternative at character 'n' line 1:20 mismatched input '<EOF>' expecting SALUTATION
Test case: we finally found an expression that results in different tree structure.
@Test
public void testCompletelyWrong() {
//compile the expression
S001HelloWordCompiler compiler = new S001HelloWordCompiler();
CommonTree ast = compiler.compile("Incorrect Expression");
//check AST structure
assertEquals(0, ast.getChildCount());
}
Error Handling in Lexer
Each lexer rule ‘RULE’ corresponds to ‘mRULE’ method in generated lexer. For example, our grammar has two rules:
SALUTATION:'Hello word'; ENDSYMBOL:'!';
and generated lexer has two corresponding methods:
public final void mSALUTATION() throws RecognitionException {
// ...
}
public final void mENDSYMBOL() throws RecognitionException {
// ...
}
Depending on what exception is thrown, lexer may or may not try to recover from it. However, each error ends in reportError(RecognitionException e) method. Generated lexer inherits it:
public void reportError(RecognitionException e) {
displayRecognitionError(this.getTokenNames(), e);
}
The result: we have to change either reportError or displayRecognitionError method in lexer.
Error Handling in Parser
Our grammar has only one parser rule ‘expression’:
expression SALUTATION ENDSYMBOL;
The expression corresponds to expression() method in generated parser:
public final expression_return expression() throws RecognitionException {
//initialization
try {
//parsing
}
catch (RecognitionException re) {
reportError(re);
recover(input,re);
retval.tree = (Object) adaptor.errorNode(input, retval.start, input.LT(-1), re);
} finally {
}
//return result;
}
If an error happens, parser will:
- report error to the console,
- recover from the error,
- add an error node (instead of an ordinary node) to the abstract syntax tree.
Error reporting in parser is little bit more complicated than error reporting in lexer:
/** Report a recognition problem.
*
* This method sets errorRecovery to indicate the parser is recovering
* not parsing. Once in recovery mode, no errors are generated.
* To get out of recovery mode, the parser must successfully match
* a token (after a resync). So it will go:
*
* 1. error occurs
* 2. enter recovery mode, report error
* 3. consume until token found in resynch set
* 4. try to resume parsing
* 5. next match() will reset errorRecovery mode
*
* If you override, make sure to update syntaxErrors if you care about that.
*/
public void reportError(RecognitionException e) {
// if we've already reported an error and have not matched a token
// yet successfully, don't report any errors.
if ( state.errorRecovery ) {
return;
}
state.syntaxErrors++; // don't count spurious
state.errorRecovery = true;
displayRecognitionError(this.getTokenNames(), e);
}
This time we have two possible options:
- replace catch clause in a parser rule method by own handling,
- override parser methods.
Antlr provides two ways how to change generated catch clause in the parser. We will create two new grammars, each demonstrates one way how to do it. In both cases, we will make parser exit upon first error.
First, we can add rulecatch to parser rule of new S002HelloWordWithErrorHandling grammar:
expression : SALUTATION ENDSYMBOL;
catch [RecognitionException e] {
//Custom handling of an exception. Any java code is allowed.
throw new S002HelloWordError(":(", e);
}
Of course, we had to add import of S002HelloWordError exception into headers block:
@parser::header {
package org.meri.antlr_step_by_step.parsers;
//add imports (see full line on Github)
import ... .S002HelloWordWithErrorHandlingCompiler.S002HelloWordError;
}
The compiler class is almost the same as before. It declares new exception:
public class S002HelloWordWithErrorHandlingCompiler extends AbstractCompiler {
public CommonTree compile(String expression) {
// no change here
}
@SuppressWarnings("serial")
public static class S002HelloWordError extends RuntimeException {
public S002HelloWordError(String arg0, Throwable arg1) {
super(arg0, arg1);
}
}
}
ANTLR will then replace default catch clause in expression rule method with our own handling:
public final expression_return expression() throws RecognitionException {
//initialization
try {
//parsing
}
catch (RecognitionException re) {
//Custom handling of an exception. Any java code is allowed.
throw new S002HelloWordError(":(", e);
} finally {
}
//return result;
}
As usually, the grammar, the compiler class and the test class are available on Github.
Alternatively, we can put rulecatch rule in between the header block and first lexer rule. This method is demonstrated in S003HelloWordWithErrorHandling grammar:
//change error handling in all parser rules
@rulecatch {
catch (RecognitionException e) {
//Custom handling of an exception. Any java code is allowed.
throw new S003HelloWordError(":(", e);
}
}
We have to add import of S003HelloWordError exception into headers block:
@parser::header {
package org.meri.antlr_step_by_step.parsers;
//add imports (see full line on Github)
import ... .S003HelloWordWithErrorHandlingCompiler.S003HelloWordError;
}
The compiler class is exactly the same as in previous case. ANTLR will replace default catch clause in all parser rules:
public final expression_return expression() throws RecognitionException {
//initialization
try {
//parsing
}
catch (RecognitionException re) {
//Custom handling of an exception. Any java code is allowed.
throw new S003HelloWordError(":(", e);
} finally {
}
//return result;
}
Again, the grammar, the compiler class and the test class are available on Github.
Unfortunately, this method has two disadvantages. First, it does not work in lexer, only in parser. Second, default report and recovery functionality works in a reasonable way. It attempts to recover from errors. Once it starts recovering, it does not generate new errors. Error messages are generated only if the parser is not in error recovery mode.
We liked this functionality, so we decided to change only default implementation of error reporting.
Add Methods and Fields to Generated Classes
We will store all lexer/parser errors in private list. Moreover, we will add two methods into generated classes:
- hasErrors – returns true if at least one error occurred,
- getErrors – returns all generated errors.
New fields and methods are added inside @members block:
@lexer::members {
//everything you need to add to the lexer
}
@parser::members {
//everything you need to add to the parser
}
members blocks must be placed between header block and first lexer rule. The example is in grammar named S004HelloWordWithErrorHandling:
//add new members to generated lexer
@lexer::members {
//add new field
private List<RecognitionException> errors = new ArrayList <RecognitionException> ();
//add new method
public List<RecognitionException> getAllErrors() {
return new ArrayList<RecognitionException>(errors);
}
//add new method
public boolean hasErrors() {
return !errors.isEmpty();
}
}
//add new members to generated parser
@parser::members {
//add new field
private List<RecognitionException> errors = new ArrayList <RecognitionException> ();
//add new method
public List<RecognitionException> getAllErrors() {
return new ArrayList<RecognitionException>(errors);
}
//add new method
public boolean hasErrors() {
return !errors.isEmpty();
}
}
Both generated lexer and generated parser contain all fields and methods written in members block.
To override a generated method, do the same thing as if you want to add a new one, e.g. add it inside @members block:
//override generated method in lexer
@lexer::members {
//override method
public void reportError(RecognitionException e) {
errors.add(e);
displayRecognitionError(this.getTokenNames(), e);
}
}
//override generated method in parser
@parser::members {
//override method
public void reportError(RecognitionException e) {
errors.add(e);
displayRecognitionError(this.getTokenNames(), e);
}
}
The method reportError now overrides default behavior in both lexer and parser.
Collect Errors in Compiler
Finally, we have to change our compiler class. New version collects all errors after input parsing phase:
private List<RecognitionException> errors = new ArrayList<RecognitionException>();
public CommonTree compile(String expression) {
try {
... init lexer ...
... init parser ...
ret = parser.expression();
//collect all errors
if (lexer.hasErrors())
errors.addAll(lexer.getAllErrors());
if (parser.hasErrors())
errors.addAll(parser.getAllErrors());
//acquire parse result
... as usually ...
} catch (RecognitionException e) {
...
}
}
/**
* @return all errors found during last run
*/
public List<RecognitionException> getAllErrors() {
return errors;
}
We must collect lexer errors after parser finished its work. The lexer is invoked from it and contain no errors before. As usually, we placed the grammar, the compiler class, and the test class on Github.
Download tag 003-S002-to-S004HelloWordWithErrorHandling of antlr-step-by-step project to find all three error handling methods in the same java project.
Reference: ANTLR Tutorial – Hello Word from our JCG partner Maria Jurcovicova at the This is Stuff blog.

How To make Error Handling in Interface GUI?
I am implementing halstead metrics.Right now i am able to parse a java file. But i don’t know how to count the operators and operands using antlr. If anybody has any idea how to count them using antlr please help me.If anybody knows tutoral or examples related to this topic please post it. It will be a great help to me.
Thank you
My good good, too.
Why to copy twice same article? are you salesman?
A JSON validator based on simplified and extensible schema build with ANTLR 4: https://github.com/zhossain-info/json-assertion