In this tutorial I would like to talk a bit about Apache Lucene. Lucene is an open-source project that provides Java-based indexing and search technology. Using its API, it is easy to implement full-text search. I will deal with the Lucene Java version, but bear in mind that there is also a .NET port available under the name Lucene.NET, as well as several helpful sub-projects.
I recently read a great tutorial about this project, but there was no actual code presented. Thus, I decided to provide some sample code to help you getting started with Lucene. The application we will build will allow you to index your own source code files and search for specific keywords.
First things first, let’s download the latest stable version from one of the Apache Download Mirrors. The version I will use is 3.0.1 so I downloaded the lucene-3.0.1.tar.gz bundle (note that the .tar.gz versions are significantly smaller than the corresponding .zip ones). Extract the tarball and locate the lucene-core-3.0.1.jar file which will be used later. Also, make sure the Lucene API JavaDoc page is open at your browser (the docs are also included in the tarball for offline usage). Next, setup a new Eclipse project, let’s say under the name “LuceneIntroProject” and make sure the aforementioned JAR is included in the project’s classpath.
Before we begin running search queries, we need to build an index, against which the queries will be executed. This will be done with the help of a class named IndexWriter, which is the class that creates and maintains an index. The IndexWriter receives Documents as input, where documents are the unit of indexing and search. Each Document is actually a set of Fields and each field has a name and a textual value. To create an IndexWriter, an Analyzer is required. This class is abstract and the concrete implementation that we will use is SimpleAnalyzer.
Enough talking already, let’s create a class named “SimpleFileIndexer” and make sure a main method is included. Here is the source code for this class:
package com.javacodegeeks.lucene;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.FSDirectory;
public class SimpleFileIndexer {
public static void main(String[] args) throws Exception {
File indexDir = new File("C:/index/");
File dataDir = new File("C:/programs/eclipse/workspace/");
String suffix = "java";
SimpleFileIndexer indexer = new SimpleFileIndexer();
int numIndex = indexer.index(indexDir, dataDir, suffix);
System.out.println("Total files indexed " + numIndex);
}
private int index(File indexDir, File dataDir, String suffix) throws Exception {
IndexWriter indexWriter = new IndexWriter(
FSDirectory.open(indexDir),
new SimpleAnalyzer(),
true,
IndexWriter.MaxFieldLength.LIMITED);
indexWriter.setUseCompoundFile(false);
indexDirectory(indexWriter, dataDir, suffix);
int numIndexed = indexWriter.maxDoc();
indexWriter.optimize();
indexWriter.close();
return numIndexed;
}
private void indexDirectory(IndexWriter indexWriter, File dataDir,
String suffix) throws IOException {
File[] files = dataDir.listFiles();
for (int i = 0; i < files.length; i++) {
File f = files[i];
if (f.isDirectory()) {
indexDirectory(indexWriter, f, suffix);
}
else {
indexFileWithIndexWriter(indexWriter, f, suffix);
}
}
}
private void indexFileWithIndexWriter(IndexWriter indexWriter, File f,
String suffix) throws IOException {
if (f.isHidden() || f.isDirectory() || !f.canRead() || !f.exists()) {
return;
}
if (suffix!=null && !f.getName().endsWith(suffix)) {
return;
}
System.out.println("Indexing file " + f.getCanonicalPath());
Document doc = new Document();
doc.add(new Field("contents", new FileReader(f)));
doc.add(new Field("filename", f.getCanonicalPath(),
Field.Store.YES, Field.Index.ANALYZED));
indexWriter.addDocument(doc);
}
}
Let’s talk a bit about this class. We provide the location of the index, i.e. where the index data will be saved on the disk (“c:/index/”). Then we provide the data directory, i.e. the directory which will be recursively scanned for input files. I have chosen my whole Eclipse workspace for this (“C:/programs/eclipse/workspace/”). Since we wish to index only for Java source code files, I also added a suffix field. You can obviously adjust those values to your search needs. The “index” method takes into account the previous parameters and uses a new instance of IndexWriter to perform the directory indexing. The “indexDirectory” method uses a simple recursion algorithm to scan all the directories for files with .java suffix. For each file that matches the criteria, a new Document is created in the “indexFileWithIndexWriter” and the appropriate fields are populated. If you run the class as a Java application via Eclipse, the input directory will be indexed and the output directory will look like the one in the following image: 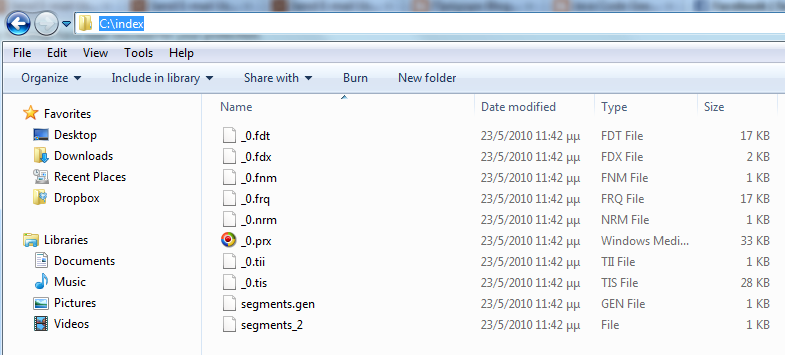 OK, we are done with the indexing, let’s move on to the searching part of the equation. For this, an IndexSearcher class is needed, which is a class that implements the main search methods. For each search, a new Query object is needed (SQL anyone?) and this can be obtained from a QueryParser instance. Note that the QueryParser has to be created using the same type of Analyzer that the index was created with, in our case using a SimpleAnalyzer. A Version is also used as constructor argument and is a class that is “Used by certain classes to match version compatibility across releases of Lucene”, according to the JavaDocs. The existence of something like that kind of confuses me, but whatever, let’s use the appropriate version for our application (Lucene_30). When the search is performed by the IndexSearcher, a TopDocs object is returned as a result of the execution. This class just represents search hits and allows us to retrieve ScoreDoc objects. Using the ScoreDocs we find the Documents that match our search criteria and from those Documents we retrieve the wanted information. Let’s see all of these in action. Create a class named “SimpleSearcher” and make sure a main method is included. The source code for this class is the following:
OK, we are done with the indexing, let’s move on to the searching part of the equation. For this, an IndexSearcher class is needed, which is a class that implements the main search methods. For each search, a new Query object is needed (SQL anyone?) and this can be obtained from a QueryParser instance. Note that the QueryParser has to be created using the same type of Analyzer that the index was created with, in our case using a SimpleAnalyzer. A Version is also used as constructor argument and is a class that is “Used by certain classes to match version compatibility across releases of Lucene”, according to the JavaDocs. The existence of something like that kind of confuses me, but whatever, let’s use the appropriate version for our application (Lucene_30). When the search is performed by the IndexSearcher, a TopDocs object is returned as a result of the execution. This class just represents search hits and allows us to retrieve ScoreDoc objects. Using the ScoreDocs we find the Documents that match our search criteria and from those Documents we retrieve the wanted information. Let’s see all of these in action. Create a class named “SimpleSearcher” and make sure a main method is included. The source code for this class is the following:
package com.javacodegeeks.lucene;
import java.io.File;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class SimpleSearcher {
public static void main(String[] args) throws Exception {
File indexDir = new File("c:/index/");
String query = "lucene";
int hits = 100;
SimpleSearcher searcher = new SimpleSearcher();
searcher.searchIndex(indexDir, query, hits);
}
private void searchIndex(File indexDir, String queryStr, int maxHits)
throws Exception {
Directory directory = FSDirectory.open(indexDir);
IndexSearcher searcher = new IndexSearcher(directory);
QueryParser parser = new QueryParser(Version.LUCENE_30,
"contents", new SimpleAnalyzer());
Query query = parser.parse(queryStr);
TopDocs topDocs = searcher.search(query, maxHits);
ScoreDoc[] hits = topDocs.scoreDocs;
for (int i = 0; i < hits.length; i++) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println(d.get("filename"));
}
System.out.println("Found " + hits.length);
}
}
We provide the index directory, the search query string and the maximum number of hits and then call the “searchIndex” method. In that method, we create an IndexSearcher, a QueryParser and a Query object. Note that QueryParser uses the name of the field that we used to create the Documents with IndexWriter (“contents”) and again that the same type of Analyzer is used (SimpleAnalyzer). We perform the search and for each Document that a match has been found, we extract the value of the field that holds the name of the file (“filename”) and we print it. That’s it, let’s perform the actual search. Run it as a Java application and you will see the names of the files that contain the query string you provided.
The Eclipse project for this tutorial, including the dependency library, can be downloaded here.
UPDATE: You can also check our subsequent post, “Did you mean” feature with Apache Lucene Spell-Checker.
Enjoy!
- “Did you mean” feature with Apache Lucene Spell-Checker
- Aspect Oriented Programming with Spring AspectJ and Maven
- Scheduling principals in Java applications
- Dependency Injection – The manual way

nice tutorial,thanks
wowwwww this like a that i found like a treasure thanx
how do i search contents of file irrespective of their extention or suffix? in the above example , you provided siuffux as “java”. How do i search in all files in a directory without specifying the suffix? what modification do I need to make?
feritz,
If you want all extensions, instead of just “java”, then you can leave out that parameter. This would change the ‘index’, ‘indexDirectory’, and ‘indexFileWithIndexWriter’ constructors to not have the parameter passed in. Finally, you would want to remove:
if (suffix!=null && !f.getName().endsWith(suffix)) {
return;
}
from the ‘indexFileWithIndexWriter’ constructor so that it does not check for extensions.
Good insight to start for Text Searching with Lucene. Will look at spell checker article also…
Thanks for the program…Can you help me with a program that can index a mysql database. Can you suggest me the steps to do the same
Hi, good example, i understood the stuff pretty well, now i am trying to execute the Lucene on my machine,
and i am facing problem with creating object ‘indexWriter’ and the SimpleAnalyzer causing me error ‘ The constructor SimpleAnalyzer() is undefined’
Hi, thanks for your tutorial.
As the question of Vishruth, in the new versions of Lucene (4.6 for me as example), there are no class SimpleAnalyzer, (or I don’t know how to find it).
So please help me to find a way to create an indexWriter.
Thank you!
Awesome!! Thank you very much for sharing. Very useful!
The SimpleAnalyzer class is available in org.apache.lucene.analysis.core package, not in org.apache.lucene.analysis. This is in Lucene 4.9.0
Hi – How to search for pdf files, when I try the above example it is showing 0 found results even after I change the suffix as pdf.
Index is working but search is not working, can you help please.
Thanks.
Nice tutorial
Hi. I am working with apache lucene 3.0.2 version. My questions are that which part of codes are responsible for opening index and opening text files? Please help me
Hi,
Very nice tutorial. Thanks for posting it. Its really very helpful.
(General info : This example is not suited to work on Java 8)
Nice tutorial. I have followed this tutorial step by step. BUt I keep getting an error when initializing my indexwriter. The error is
rejected Lorg/apache/lucene/index/IndexWriter;.slowFileExists (Lorg/apache/lucene/store/Directory;Ljava/lang/String;)Z
rejecting opcode 0x0d at 0x000e
rejected Lorg/apache/lucene/index/IndexWriter;.slowFileExists (Lorg/apache/lucene/store/Directory;Ljava/lang/String;)Z
java.lang.VerifyError: org/apache/lucene/index/IndexWriter
Any form of assistance would be appreciated. Thank you.
Though the tutorial is good but it would have been even better if there was more theoretical information about indexing and searching.
i wanna know how to index a docx file in lucene and search the content from it
Great tutorial,
But how can i count terms frequencies (printing ligne number for example ) for each Document ?
Think U
Hey thank you very much,i was searching in hirarchy of directory but was not coming previously,when i went through your code its working properly,but it has some issue like from some files any content is not finding and .docx files also have same issue but o will do that,any way thank you Cheris Aiken..
hey i am not able to search text from pdf file i.e. some text is searched but most of the text is not searched why?